
Last Week in Character Technology - 6.1.25-6.6.25
Pixel3DMM Code Drop, In browser 4D Gaussian Splats, Ultra Detailed Human Avatars, and more!

This week was a bit too busy for me to do the daily updates, so I’m aggregating last weeks more significant news into one drop. We definitely saw some impressive stuff this week, so there’s a lot to cover.
One call out - definitely take a look at thee Interactive Demos for FreeT
imeGS. While this is one of those more all-encompassing pieces of research not specifically focused on characters, it is really impressive. You can interact with a full 4DGS reconstruction in your web browser. I’m writing this now on an old 2016 linux workstation with a GTX 1080 and it ran perfectly smooth.
Pixel3DMM Code Release
In the 5.2.22 update, I covered Pixel3DMM a state-of-the-art face tracker. Thursday, the team finally released the code for your viewing pleasure.

I’ve been exploring a one-shot animatable character pipeline and I had a chance to play around with Pixel3DMM a bit on a local RTX 4090 machine. It’s quite impressive.
If you would like to try it out and you’re on a Windows machine, I highly recommend doing it through WSL (Windows Subsystem for Linux), as you’ll encounter a lot of dependency issues if you try to install on native windows. It installs pretty pain free on Ubuntu through WSL, though you may need to resolve a few dependency issues (in my case it was with pytorch3D, which I needed to build locally in my conda env).
It is truly impressive that we can do this from monocular video, but I do want to take a moment to dispel any notion that it could, in its current state, be a high-end 4D killer when it comes to production quality assets in the film or games industry. At the end of the day, while this project significantly increases the accuracy of the optimization of FLAME, the production utility is still unfortunately limited by the resolution of the mesh and lacks some precision in the eyelids and mouth.
I would compare the final mesh output most closely to the old MOVA data, if you ever had a chance to see that. MOVA was incredible tech for the time, but was fairly low res and not at the level of detail you might get from working with more modern 4D processes like those employed by Di4D, Ecco, or Infinite Realities. If the estimated normals were utilized to upres the mesh, however, we’d be getting into competitive territory - which is a step I’m sure is on the horizon.
At any rate, I don’t want to downplay the amazing achievement here. If you’d have told me in 2010 this would be possible, I’m not sure I could have comprehended it. This is really really incredible work and a huge congrats to the research team on this amazing achievement. I can easily imagine dozens of significant uses.
Check out the code here.
State of Unreal
Moving on - Tuesday we saw Epic’s State of Unreal, which may be one of the more significant updates to Unreal in terms of Character Technology. Thus far, I’ve kept this blog more focused on emerging research, but as with Google IO a few weeks ago - big events like these provide us with a look at how all this amazing academic research and tribal industry knowledge makes its way into a polished commercial product.
In this case we see flesh and muscle systems in Chaos Flesh, 3DMM’s in the ML Deformer, Monocular Pose-estimation for bodies and faces with the Metahuman Animator updates, and an expression editor that allows artists to modify the FACS-like Metahuman shape set.
A huge shout-out to many former friends and colleagues who are now a part of the team at Epic behind driving some of this incredible tech.
FreeTimeGS: Free Gaussians at Anytime and Anywhere for Dynamic Scene Reconstruction
Yifan Wang · Peishan Yang · Zhen Xu · Jiaming Sun · Zhanhua Zhang · Yong Chen · Hujun Bao · Sida Peng · Xiaowei Zhou
1Zhejiang University
2Geely Automobile Research Institute
📄 Paper: https://arxiv.org/pdf/2506.05348
🚧 Project: https://zju3dv.github.io/freetimegs/
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2506.05348
Interactive Demos: https://www.4dv.ai/viewer/salmon_10s?showdemo=4dv
This paper addresses the challenge of reconstructing dynamic 3D scenes with complex motions. Some recent works define 3D Gaussian primitives in the canonical space and use deformation fields to map canonical primitives to observation spaces, achieving real-time dynamic view synthesis. However, these methods often struggle to handle scenes with complex motions due to the difficulty of optimizing deformation fields. To overcome this problem, we propose FreeTimeGS, a novel 4D representation that allows Gaussian primitives to appear at arbitrary time and locations. In contrast to canonical Gaussian primitives, our representation possesses the strong flexibility, thus improving the ability to model dynamic 3D scenes. In addition, we endow each Gaussian primitive with a motion function, allowing it to move to neighboring regions over time, which reduces the temporal redundancy. Experiments results on several datasets show that the rendering quality of our method outperforms recent methods by a large margin.
SmartAvatar: Text- and Image-Guided Human Avatar Generation with VLM AI Agents
Alexander Huang‑Menders · Xinhang Liu · Andy Xu · Yuyao Zhang · Chi‑Keung Tang · Yu‑Wing Tai
1The Hong Kong University of Science and Technology
2Dartmouth College



📄 Paper: https://arxiv.org/pdf/2506.04606
🚧 Project: N/A
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2506.04606
SmartAvatar is a vision-language-agent-driven framework for generating fully rigged, animation-ready 3D human avatars from a single photo or textual prompt. While diffusion-based methods have made progress in general 3D object generation, they continue to struggle with precise control over human identity, body shape, and animation readiness. In contrast, SmartAvatar leverages the commonsense reasoning capabilities of large vision-language models (VLMs) in combination with off-the-shelf parametric human generators to deliver high-quality, customizable avatars. A key innovation is an autonomous verification loop, where the agent renders draft avatars, evaluates facial similarity, anatomical plausibility, and prompt alignment, and iteratively adjusts generation parameters for convergence. Quantitative benchmarks and user studies demonstrate that SmartAvatar outperforms recent text- and image-driven avatar generation systems in terms of reconstructed mesh quality, identity fidelity, attribute accuracy, and animation readiness, making it a versatile tool for realistic, customizable avatar creation on consumer-grade hardware.
UMA: Ultra‑detailed Human Avatars via Multi‑level Surface Alignment
Heming Zhu, Guoxing Sun, Christian Theobalt, Marc Habermann
Max Planck Institute for Informatics, Saarland Informatics Campus
Saarbrücken Research Center for Visual Computing, Interaction and AI
📄 Paper: https://arxiv.org/pdf/2506.01802
🚧 Project: N/A
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2506.01802

Learning an animatable and clothed human avatar model with vivid dynamics and photorealistic appearance from multi-view videos is an important foundational research problem in computer graphics and vision. Fueled by recent advances in implicit representations, the quality of animatable avatars has improved by attaching representations to drivable template meshes. However, they usually fail to preserve the highest level of detail when zoomed in or at 4K resolution due to inaccurate surface tracking—depth misalignment and surface drift between the template and ground truth. To address this, we introduce UMA: a method leveraging latent per-frame deformation codes and a multi-level surface alignment strategy using 2D point trackers. This includes depth alignment via latent conditioning, vertex-level alignment using rendered-to-image 2D tracks lifted into 3D, and texel-level alignment enforcing fine correspondence for Gaussian texture splats. We also contribute a new dataset: five 10+ minute multi-view 6K video sequences capturing clothing with complex textures and dynamic wrinkles. UMA significantly outperforms prior state-of-the-art methods in rendering quality and geometric fidelity, recovering ultra-fine details like cloth wrinkles and patterns while maintaining temporal coherence.
Low‑Rank Head Avatar Personalization with Registers
Sai Tanmay Reddy Chakkera, Aggelina Chatziagapi, Md Moniruzzaman, Chen-Ping Yu, Yi-Hsuan Tsai, Dimitris Samaras
1Stony Brook University
2Atmanity Inc.
📄 Paper: https://arxiv.org/pdf/2506.01935
🚧 Project: https://starc52.github.io/publications/2025-05-28-LoRAvatar/
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2506.01935
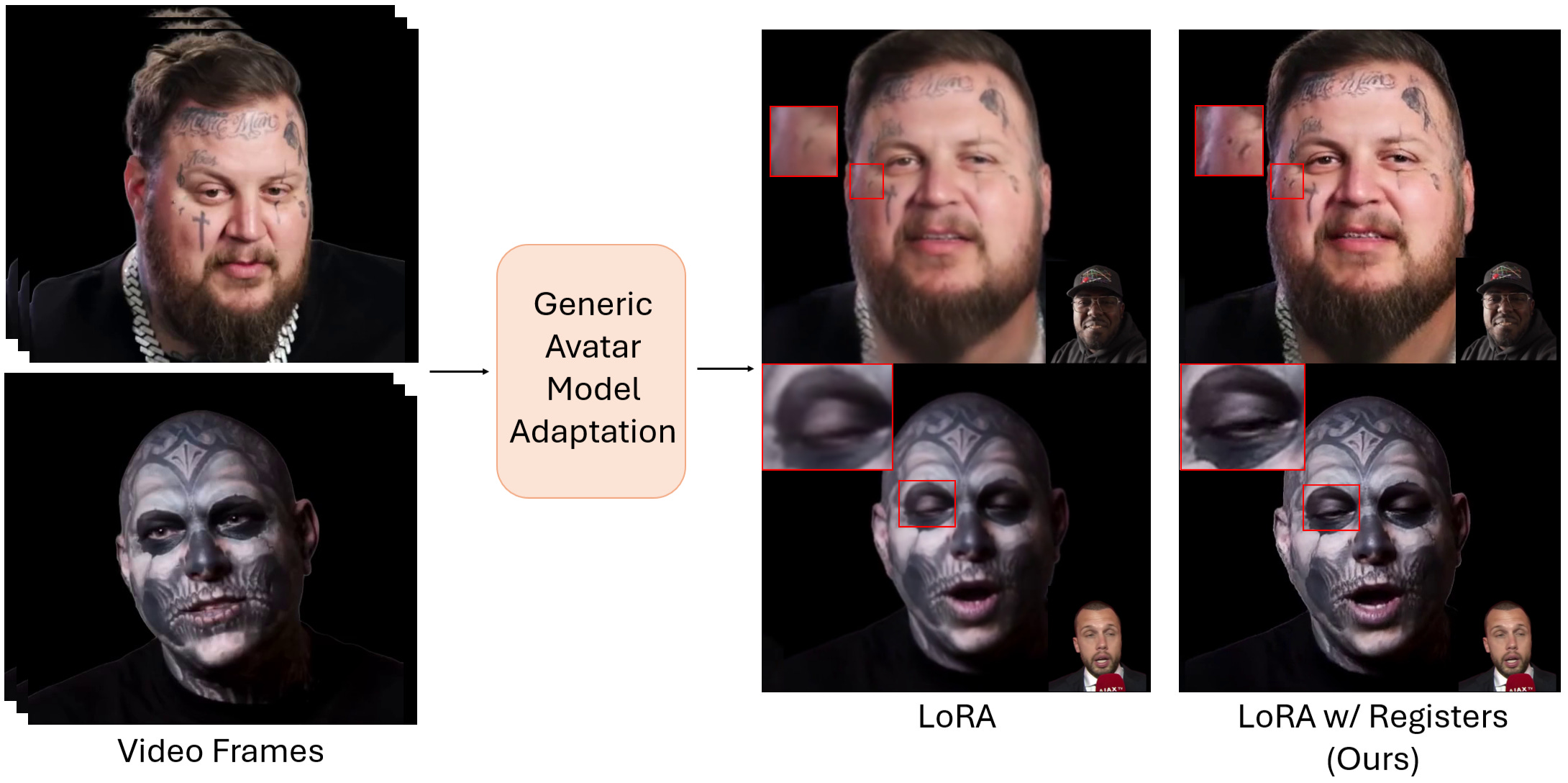
We introduce a novel method for low-rank personalization of a generic model for head avatar generation. Prior work proposes generic models that achieve high-quality face animation by leveraging large-scale datasets of multiple identities. However, such generic models usually fail to synthesize unique identity-specific details, since they learn a general domain prior. To adapt to specific subjects, we find that it is still challenging to capture high-frequency facial details via popular solutions like low-rank adaptation (LoRA). This motivates us to propose a specific architecture, a Register Module, that enhances the performance of LoRA, while requiring only a small number of parameters to adapt to an unseen identity. Our module is applied to intermediate features of a pre-trained model, storing and re-purposing information in a learnable 3D feature space. To demonstrate the efficacy of our personalization method, we collect a dataset of talking videos of individuals with distinctive facial details, such as wrinkles and tattoos. Our approach faithfully captures unseen faces, outperforming existing methods quantitatively and qualitatively. We will release the code, models, and dataset to the public.
From Motion to Behavior: Hierarchical Modeling of Humanoid Generative Behavior Control
Jusheng Zhang, Jinzhou Tang, Sidi Liu, Mingyan Li, Sheng Zhang, Jian Wang, Keze Wang
Sun Yat-sen University
University of Maryland, College Park
Snap Inc.
📄 Paper: https://arxiv.org/pdf/2506.00043
🚧 Project: N/A
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2506.00043
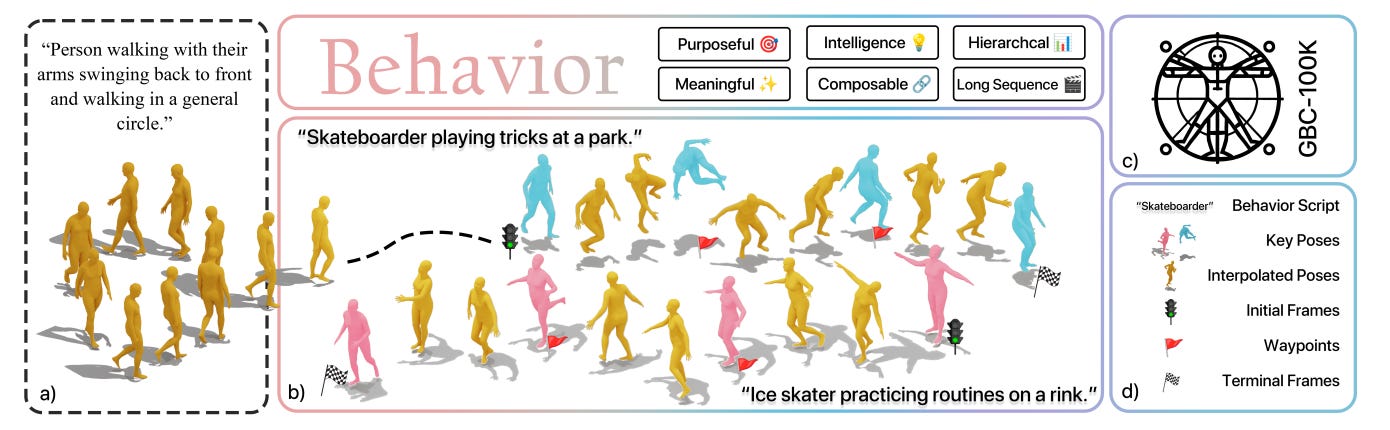
Human motion generative modeling or synthesis aims to characterize complicated human motions of daily activities in diverse real-world environments. However, current research predominantly focuses on either low-level, short-period motions or high-level action planning, without taking into account the hierarchical goal-oriented nature of human activities. In this work, we take a step forward from human motion generation to human behavior modeling, which is inspired by cognitive science. We present a unified framework, dubbed Generative Behavior Control (GBC), to model diverse human motions driven by various high-level intentions by aligning motions with hierarchical behavior plans generated by large language models (LLMs). Our insight is that human motions can be jointly controlled by task and motion planning in robotics, but guided by LLMs to achieve improved motion diversity and physical fidelity. Meanwhile, to overcome the limitations of existing benchmarks, i.e., lack of behavioral plans, we propose GBC-100K dataset annotated with a hierarchical granularity of semantic and motion plans driven by target goals. Our experiments demonstrate that GBC can generate more diverse and purposeful high-quality human motions with 10× longer horizons compared with existing methods when trained on GBC-100K, laying a foundation for future research on behavioral modeling of human motions. Our dataset and source code will be made publicly available.
HunyuanVideo‑Avatar: High‑Fidelity Audio‑Driven Human Animation for Multiple Characters
Yi Chen, Sen Liang, Zixiang Zhou, Ziyao Huang, Yifeng Ma, Junshu Tang, Qin Lin, Yuan Zhou, Qinglin Lu
Tencent Hunyuan
🚧 Project: https://hunyuanvideo-avatar.github.io
💻 Code: https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar
📄 Paper: https://arxiv.org/pdf/2505.20156
❌ ArXiv: https://arxiv.org/abs/2505.20156

Recent years have witnessed significant progress in audio-driven human animation. However, critical challenges remain in (i) generating highly dynamic videos while preserving character consistency, (ii) achieving precise emotion alignment between characters and audio, and (iii) enabling multi-character audio-driven animation. Current audio-driven human animation methods can be broadly categorized into two paradigms: portrait animation and full-body animation. Portrait animation methods focus exclusively on facial movements while maintaining static or simplistic backgrounds, while full-body methods often fail to produce emotionally expressive or synchronized outputs in multi-character settings. This paper introduces HunyuanVideo‑Avatar, a novel system capable of driving multiple human characters from audio inputs with high fidelity, emotion consistency, and dynamic full-body motion across varied backgrounds and expressive styles.
Thanks for taking the time to put together this great newsletter Josh! Great idea. Was wondering what you thought of Pixel3DMM as a possible "head tracker"? I'm using some off the shelf tools but looking for a more automated solution. Wondering if there's any animated transform generated representing the head motion here? Thanks again Josh and hope all is well!