
Today in Character Technology - 5.2.25
Pixel3DMM - a big improvement on 3DMM optimization / monocular face tracking, and enhanced detail recovery for monocular gaussian avatars.

Today begins with a nice, meaty Character Tech paper - Pixel3DMM - which is referred to as “a set of highly-generalized vision transformers which predict per-pixel geometric cues in order to constrain the optimization of a 3D morphable face model.”

This paper builds on the work of FLAME and DINOv2 with augmentation from NPHM, FaceScape and Ava256. If you’ve been following similar research in this category (several examples of which have even been featured in the last few weeks of posts here), one thing that may be immediately apparent is the quality of Pixel3DMM seems like a clear step forward in terms of likeness and stability. FLAME has become a ubiquitous foundation and benchmark, but it’s immediately apparent to a keen observer that it is only a rough approximation.
What’s important to takeaway here - this paper doesn’t propose a new 3DMM to compete with FLAME, but rather improves FLAME by developing a new way to optimize its parameters to achieve what appears to be a much more accurate and consistent fitting than we’ve seen in other papers.
We also have a more minor addition focusing on improving detail in monocular gaussian avatar reconstruction, which unfortunately lacks any code or videos for qualitative evaluation.
Cheers
Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction
Simon Giebenhain, Tobias Kirschstein, Martin Rünz, Lourdes Agapito, Matthias Nießner
Technical University of Munich
Synthesia
University College London
🚧Project: https://simongiebenhain.github.io/pixel3dmm/
📄Paper: https://arxiv.org/pdf/2505.00615
💻Code: (coming)
❌ArXiv: https://arxiv.org/abs/2505.00615

We address the 3D reconstruction of human faces from a single RGB image. To this end, we propose Pixel3DMM, a set of highly-generalized vision transformers which predict per-pixel geometric cues in order to constrain the optimization of a 3D morphable face model (3DMM). We exploit the latent features of the DINO foundation model, and introduce a tailored surface normal and uv-coordinate prediction head. We train our model by registering three high-quality 3D face datasets against the FLAME mesh topology, which results in a total of over 1,000 identities and 976K images. For 3D face reconstruction, we propose a FLAME fitting opitmization that solves for the 3DMM parameters from the uv-coordinate and normal estimates. To evaluate our method, we introduce a new benchmark for single-image face reconstruction, which features high diversity facial expressions, viewing angles, and ethnicities. Crucially, our benchmark is the first to evaluate both posed and neutral facial geometry. Ultimately, our method outperforms the most competitive baselines by over 15% in terms of geometric accuracy for posed facial expressions.
Comments:Project Website: this https URL ; Video: this https URLSubjects:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)Cite as:arXiv:2505.00615 [cs.CV]
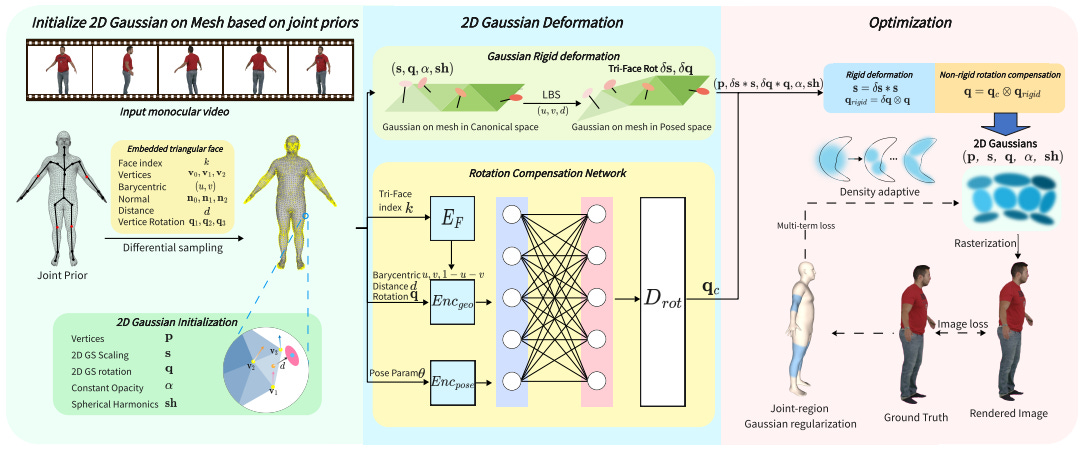
Real-Time Animatable 2DGS-Avatars with Detail Enhancement from Monocular Videos
Xia Yuan, Hai Yuan, Wenyi Ge, Ying Fu, Xi Wu, Guanyu Xing
🚧Project: N/A
📄Paper: https://arxiv.org/pdf/2505.00421
💻Code: N/A
❌ArXiv: https://arxiv.org/abs/2505.00421
High-quality, animatable 3D human avatar reconstruction from monocular videos offers significant potential for reducing reliance on complex hardware, making it highly practical for applications in game development, augmented reality, and social media. However, existing methods still face substantial challenges in capturing fine geometric details and maintaining animation stability, particularly under dynamic or complex poses. To address these issues, we propose a novel real-time framework for animatable human avatar reconstruction based on 2D Gaussian Splatting (2DGS). By leveraging 2DGS and global SMPL pose parameters, our framework not only aligns positional and rotational discrepancies but also enables robust and natural pose-driven animation of the reconstructed avatars. Furthermore, we introduce a Rotation Compensation Network (RCN) that learns rotation residuals by integrating local geometric features with global pose parameters. This network significantly improves the handling of non-rigid deformations and ensures smooth, artifact-free pose transitions during animation. Experimental results demonstrate that our method successfully reconstructs realistic and highly animatable human avatars from monocular videos, effectively preserving fine-grained details while ensuring stable and natural pose variation. Our approach surpasses current state-of-the-art methods in both reconstruction quality and animation robustness on public benchmarks.
Subjects:Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2505.00421 [cs.CV]
Adjacent Research
Eye2Eye: A Simple Approach for Monocular-to-Stereo Video Synthesis
This work introduces a method to convert a text-to-video generator into a video-to-stereo generator that directly synthesizes a shifted viewpoint from an input video, enabling 3D stereoscopic effects without depth estimation or warping.
Unlike traditional multi-step methods relying on disparity maps and inpainting, this approach leverages a pre-trained video model’s priors to synthesize new views directly — improving results in scenes with specular or transparent surfaces.