
Today in Character Technology 8.21.25
3d human gaussians from two images, an interesting medical research paper that may interest anyone who has experience fitting facial point clouds, and multi-skeleton contrastive learning.

After a week of summer travel extended itself to over a month, I’ve been neglecting the updates as I get back into the swing of things. So many big developments in that timeframe, which I’d like to go back and gather up into a post at some point.
In the meantime, here’s what’s hot off the presses for today. 3d human gaussians from two images, an interesting medical research paper that may interest anyone who has experience fitting facial point clouds, and multi-skeleton contrastive learning.
Snap-Snap: Taking Two Images to Reconstruct 3D Human Gaussians in Milliseconds
Jia Lu, Taoran Yi, Jiemin Fang, Chen Yang, Chuiyun Wu, Wei Shen, Wenyu Liu, Qi Tian, Xinggang Wang
1Huazhong University of Science and Technology
2Huawei Inc.
3Shanghai Jiaotong University
🚧 Project: https://hustvl.github.io/Snap-Snap/
📄 Paper: https://arxiv.org/pdf/2508.14892
❌ ArXiv: https://arxiv.org/abs/2508.14892
💻 Code: https://github.com/hustvl/Snap-Snap
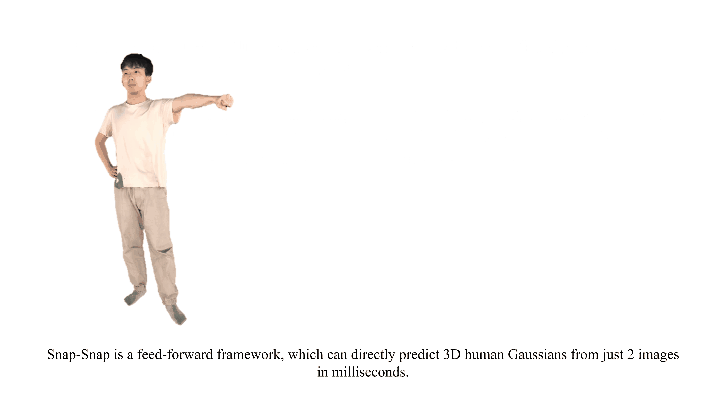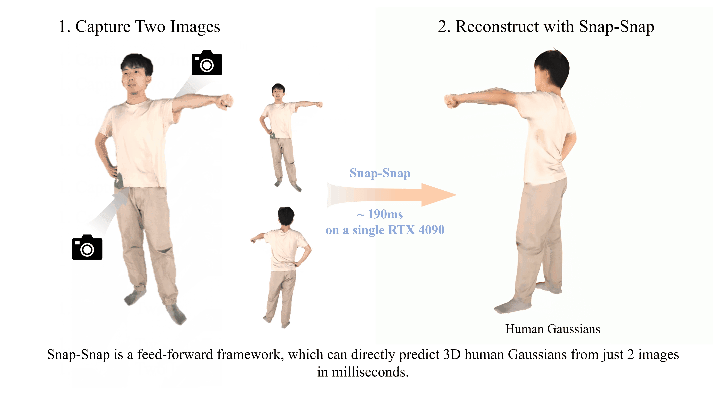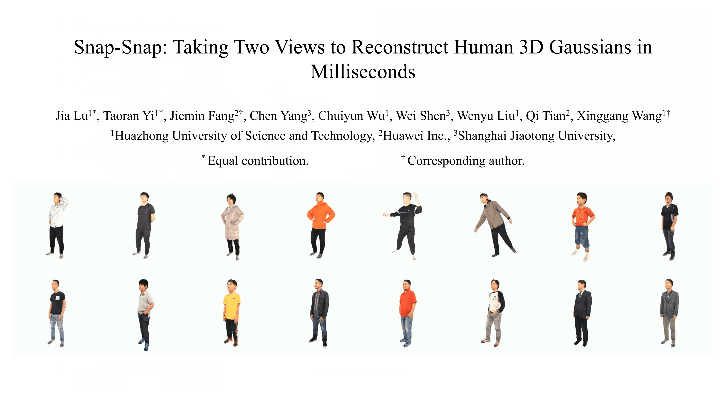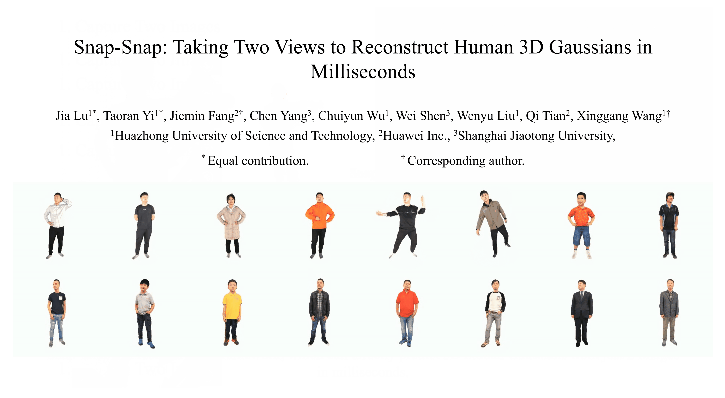
Reconstructing 3D human bodies from sparse views has been an appealing topic, which is crucial to broader the related applications. In this paper, we propose a quite challenging but valuable task to reconstruct the human body from only two images, i.e., the front and back view, which can largely lower the barrier for users to create their own 3D digital humans. The main challenges lie in the difficulty of building 3D consistency and recovering missing information from the highly sparse input.
We redesign a geometry reconstruction model based on foundation reconstruction models to predict consistent point clouds even input images have scarce overlaps with extensive human data training. Furthermore, an enhancement algorithm is applied to supplement the missing color information, and then the complete human point clouds with colors can be obtained, which are directly transformed into 3D Gaussians for better rendering quality.
Experiments show that our method can reconstruct the entire human in 190 ms on a single NVIDIA RTX 4090, with two images at a resolution of 1024×1024, demonstrating state‑of‑the‑art performance on the THuman2.0 and cross‑domain datasets. Additionally, our method can complete human reconstruction even with images captured by low‑cost mobile devices, reducing the requirements for data collection.
TCFNet: Bidirectional Face-Bone Transformation via a Transformer-based Coarse-to-Fine Point Movement Network
Runshi Zhang, Bimeng Jie, Yang He, Junchen Wang
School of Mechanical Engineering and Automation, Beihang University
Peking University School and Hospital of Stomatology
🚧 Project: N/A
📄 Paper: https://arxiv.org/pdf/2508.14373
❌ ArXiv: https://arxiv.org/abs/2508.14373
💻Code: https://github.com/Runshi-Zhang/TCFNet

Computer‑aided surgical simulation is a critical component of orthognathic surgical planning, where accurately simulating face‑bone shape transformations is significant. The traditional biomechanical simulation methods are limited by their computational time consumption levels, labor‑intensive data processing strategies and low accuracy.
Recently, deep learning‑based simulation methods have been proposed to view this problem as a point‑to‑point transformation between skeletal and facial point clouds. However, these approaches cannot process large‑scale points, have limited receptive fields that lead to noisy points, and employ complex preprocessing and postprocessing operations based on registration. These shortcomings limit the performance and widespread applicability of such methods.
Therefore, we propose a Transformer‑based coarse‑to‑fine point movement network (TCFNet) to learn unique, complicated correspondences at the patch and point levels for dense face‑bone point cloud transformations. This end‑to‑end framework adopts a Transformer‑based network and a local information aggregation network (LIA‑Net) in the first and second stages, respectively, which reinforce each other to generate precise point movement paths.
LIA‑Net can effectively compensate for the neighborhood precision loss of the Transformer‑based network by modeling local geometric structures (edges, orientations and relative position features). The previous global features are employed to guide the local displacement using a gated recurrent unit.
Inspired by deformable medical image registration, we propose an auxiliary loss that can utilize expert knowledge for reconstructing critical organs. Compared with the existing state‑of‑the‑art (SOTA) methods on gathered datasets, TCFNet achieves outstanding evaluation metrics and visualization results. The code is available at the provided GitHub link. arxiv.org
MS-CLR: Multi-Skeleton Contrastive Learning for Human Action Recognition
Mert Kiray, Alvaro Ritter, Nassir Navab, Benjamin Busam
Technical University of Munich
3Dwe.ai
🚧 Project: N/A
📄 Paper: https://arxiv.org/pdf/2508.14889
❌ ArXiv: https://arxiv.org/abs/2508.14889
💻Code: https://3dwe-ai.github.io/ms-clr/

Contrastive learning has gained significant attention in skeleton‑based action recognition for its ability to learn robust representations from unlabeled data. However, existing methods rely on a single skeleton convention, which limits their ability to generalize across datasets with diverse joint structures and anatomical coverage.
We propose Multi‑Skeleton Contrastive Learning (MS‑CLR), a general self‑supervised framework that aligns pose representations across multiple skeleton conventions extracted from the same sequence. This encourages the model to learn structural invariances and capture diverse anatomical cues, resulting in more expressive and generalizable features. To support this, we adapt the ST‑GCN architecture to handle skeletons with varying joint layouts and scales through a unified representation scheme.
Experiments on the NTU RGB+D 60 and 120 datasets demonstrate that MS‑CLR consistently improves performance over strong single‑skeleton contrastive learning baselines. A multi‑skeleton ensemble further boosts performance, setting new state‑of‑the‑art results on both datasets
Adjacent Research
Making Pose Representations More Expressive and Disentangled via Residual Vector Quantization
The authors enhance text‑to‑motion generation by introducing residual vector quantization (RVQ) to augment discrete pose codes with continuous motion features. This preserves interpretability while capturing fine-grained motion, significantly improving both FID (from 0.041 to 0.015) and Top‑1 R‑Precision (from 0.508 to 0.510) on HumanML3D, and demonstrating refined controllability for motion editing.
GOGS: High-Fidelity Geometry and Relighting for Glossy Objects via Gaussian Surfels
GOGS introduces a two-stage inverse rendering framework using 2D Gaussian surfels to reconstruct glossy object geometry and enable photorealistic relighting. It combines a physics-based rendering surface reconstruction with Monte Carlo-based material decomposition, achieving state‑of‑the‑art performance in geometry accuracy, material separation, and novel illumination rendering.
GeMS: Efficient Gaussian Splatting for Extreme Motion Blur
GeMS addresses the problem of reconstructing 3D scenes from extremely motion-blurred images by integrating three key innovations: VGGSfM (a deep-learning SfM that works directly on blurred inputs), a 3DGS-MCMC initialization to avoid heuristic densification, and joint optimization of camera poses and Gaussian parameters. It also introduces GeMS-E, which leverages event-based deblurring when available, achieving state-of-the-art reconstruction for both synthetic and real-world datasets.
DreamSwapV: Mask-guided Subject Swapping for Any Customized Video Editing
DreamSwapV is a universal, mask-guided framework for video subject swapping. Given any source video, a user-provided mask, and a reference image, it swaps out the subject in a subject-agnostic, end-to-end manner. The model incorporates multi-condition fusion and an adaptive mask strategy to handle varying scales and interactions, outperforming existing methods on VBench metrics and establishing a new DreamSwapV‑Benchmark