
Today in Character Technology - 5.8.25
Turn you sketches into a 3D Model with S3D and 3D Human Pose Estimation with increased accuracy and speed.

5.9.25 was quite busy so I’m posting this late, but fortunately it was a fairly light day in research land.
Both papers today have code, which is always appreciated. First up - traditional artists rejoice, you can turn your pencil sketches into 3D models! And then, more work in the realm of 3D Human Pose Estimation, which continues to produce better and better pose estimation from consumer grade inputs.
Enjoy!
S3D: Sketch-Driven 3D Model Generation
Hail Song, Wonsik Shin, Naeun Lee, Soomin Chung, Nojun Kwak, Woontack Woo
KAIST, Seoul National University
🚧 Project: https://github.com/hailsong/S3D
📄 Paper: https://arxiv.org/pdf/2505.04185
💻 Code: https://github.com/hailsong/S3D
❌ ArXiv: https://arxiv.org/abs/2505.04185

Generating high-quality 3D models from 2D sketches is a challenging task due to the inherent ambiguity and sparsity of sketch data. In this paper, we present S3D, a novel framework that converts simple hand-drawn sketches into detailed 3D models. Our method utilizes a U-Net-based encoder-decoder architecture to convert sketches into face segmentation masks, which are then used to generate a 3D representation that can be rendered from novel views. To ensure robust consistency between the sketch domain and the 3D output, we introduce a novel style-alignment loss that aligns the U-Net bottleneck features with the initial encoder outputs of the 3D generation module, significantly enhancing reconstruction fidelity. To further enhance the network's robustness, we apply augmentation techniques to the sketch dataset. This streamlined framework demonstrates the effectiveness of S3D in generating high-quality 3D models from sketch inputs.
HDiffTG: A Lightweight Hybrid Diffusion-Transformer-GCN Architecture for 3D Human Pose Estimation
Yajie Fu, Chaorui Huang, Junwei Li, Hui Kong, Yibin Tian, Huakang Li, Zhiyuan Zhang
College of Information Science and Electronic Engineering, Zhejiang University, China
Faculty of Science and Technology, University of Macau, China
College of Mechatronics and Control Engineering, Shenzhen University, China
School of AI and Advanced Computing, Xi’an Jiaotong-Liverpool University, China
School of Computing and Information Systems, Singapore Management University, Singapore
🚧 Project: https://github.com/CirceJie/HDiffTG
📄 Paper: https://arxiv.org/pdf/2505.04276
💻 Code: https://github.com/CirceJie/HDiffTG
❌ ArXiv: https://arxiv.org/abs/2505.04276
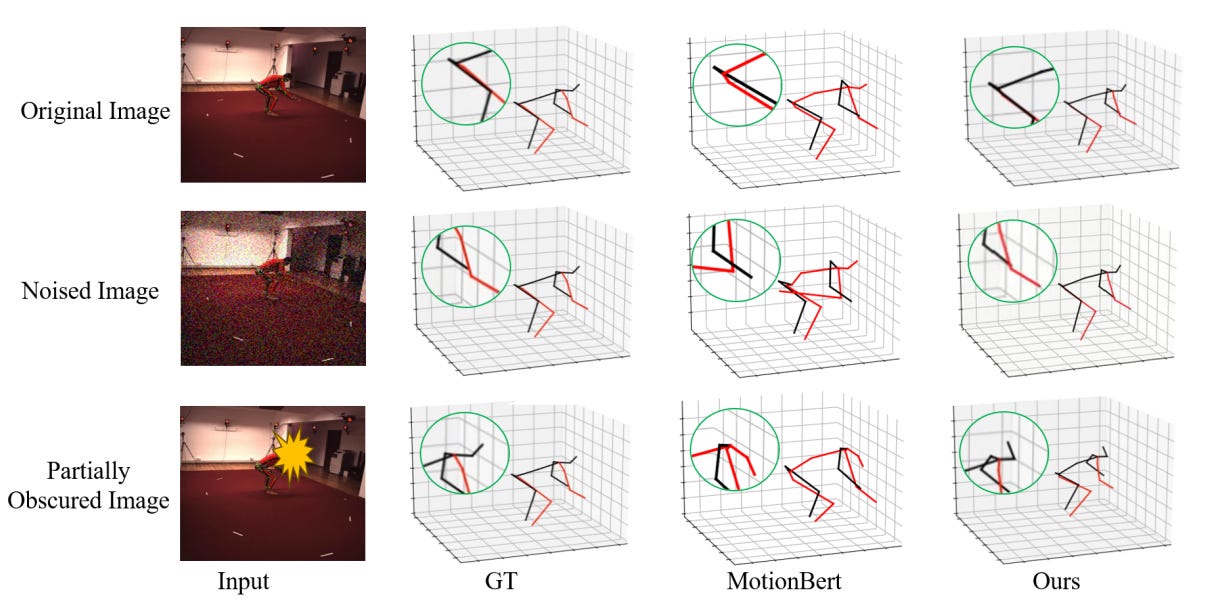
We propose HDiffTG, a novel 3D Human Pose Estimation (3DHPE) method that integrates Transformer, Graph Convolutional Network (GCN), and diffusion model into a unified framework. HDiffTG leverages the strengths of these techniques to significantly improve pose estimation accuracy and robustness while maintaining a lightweight design. The Transformer captures global spatiotemporal dependencies, the GCN models local skeletal structures, and the diffusion model provides step-by-step optimization for fine-tuning, achieving a complementary balance between global and local features. This integration enhances the model's ability to handle pose estimation under occlusions and in complex scenarios. Furthermore, we introduce lightweight optimizations to the integrated model and refine the objective function design to reduce computational overhead without compromising performance. Evaluation results on the Human3.6M and MPI-INF-3DHP datasets demonstrate that HDiffTG achieves state-of-the-art (SOTA) performance on the MPI-INF-3DHP dataset while excelling in both accuracy and computational efficiency. Additionally, the model exhibits exceptional robustness in noisy and occluded environments.
Adjacent Research
Bridging Geometry-Coherent Text-to-3D Generation with Multi-View Diffusion Priors and Gaussian Splatting
This paper introduces Coupled Score Distillation (CSD), a method that enhances text-to-3D generation by enforcing multi-view geometric consistency and enabling direct optimization of 3D Gaussian Splatting for high-quality 3D content.
CAD-Llama: Leveraging Large Language Models for Computer-Aided Design Parametric 3D Model Generation
CAD-Llama enhances large language models for parametric 3D CAD generation by introducing a structured code format, a hierarchical annotation pipeline, and an adaptive pretraining approach tailored to spatial reasoning.
Edge-GPU Based Face Tracking for Face Detection and Recognition Acceleration
This work proposes a hardware-software co-design using NVIDIA Jetson AGX Orin to accelerate real-time face recognition with integrated face tracking, significantly boosting throughput and reducing power consumption.