
Today in Character Technology - 5.22.25
Towards broader applications of 4D with Expressive Virtual Avatars from Multi-view Videos, Co-speech Gesture Synthesis with intentionality, Decoupled Whole-Body, Audio-Driven Avatars and more...

Since the early 2000s, sequential photogrammetry and mesh tracking (or “4D scanning” as it’s better known) has gained traction in both film and game development. While most focus on the face, a number of studios and vendors have also been doing full body 4D, though it’s seen limited application in real-world production thus far.
If you’ve ever had the privilege of working with 4D data - it is a technical artist’s dream - millimeter precision sequential mesh data at 30-60fps that captures all of that amazing skin, muscle, and clothing movement in all of its weird and natural beauty.
I absolutely love working with 4D and have the utmost admiration and respect for all of those involved in developing, capturing and processing it - it’s a truly heroic effort to build these scanning rigs, synchronize the lighting and cameras, transfer and store the data, and process the source images into usable coherent mesh data.
That said, the challenges with 4D data are not trivial - it’s difficult to capture, time consuming to produce, challenging to work with, can hog upwards of 1TB/minute, and thus is expensive to acquire - making it inaccessible for anything but the most high-end use cases. There are also significant challenges when it comes to getting unstructured full body sequences onto a usable coherent mesh. The challenges don’t end with acquisition. To use it in production requires custom pipelines, tools, and specialized software to really work with in any meaningful way. Capture rigs targeting the whole body also don’t typically produce facial data that is high enough quality to use directly in high-end facial authoring pipelines.
So while I would always prefer captured 4D for principal assets (main characters, etc) - when I saw Vid2Avatar in CVPR 2023, I was very excited to see the first signs of what looked like a real path towards scaling the utilization of 4D data in all those cases where it would be too costly or impractical to capture it.

Since then, there have been a number of steps forward in this domain, and we start today’s research strong with the latest. EVA brings us an appreciable step closer to broader use-cases for 4D data. It should be noted - the guidance meshes here are still somewhat low-resolution, and much of the detail we’re seeing comes from the textural 3DGS layer.
So while I think most would still prefer the utilization of the higher-end scanned data for faces in productions where quality is paramount, the ability to recover reasonably accurate full-body motion data on a coherent mesh from un-synchronized consumer-grade video opens up the potential of utilizing 4D data in many previously untenable production scenarios and applications. Not only for consumers, but for scanning vendors themselves.
The authors haven’t stated whether or not they will release the code, but their sister department (Max Planck Institute for Intelligent Systems in Stuttgart) typically releases their code and models to the public - so fingers crossed.
Aside from this, we see a number of other interesting papers today. Notably, Intentional Gesture moves a step ahead in co-speech gesture synthesis. If you’ve followed this area closely, you may notice that while the gestures typically align well with the cadence of speech - they are often not particularly punchy or meaningful. IG aims to bridge the gap here with a new dataset and their “Intentional Gesture Motion Tokenizer.” The project page doesn’t appear live yet, but we’ll look forward to getting a closer look when it is.
Anyway, today was a bigger drop with at least 5 relevant papers and 7 adjacent, so off to it.
Cheers.
EVA: Expressive Virtual Avatars from Multi-view Videos
Hendrik Junkawitsch, Guoxing Sun, Heming Zhu, Christian Theobalt, Marc Habermann
Max Planck Institute for Informatics, Saarland Germany
Saarbrucken Research Center for Visual Computing, Interaction and AI
🚧 Project: https://vcai.mpi-inf.mpg.de/projects/EVA/
📄 Paper: https://arxiv.org/pdf/2505.15385
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2505.15385

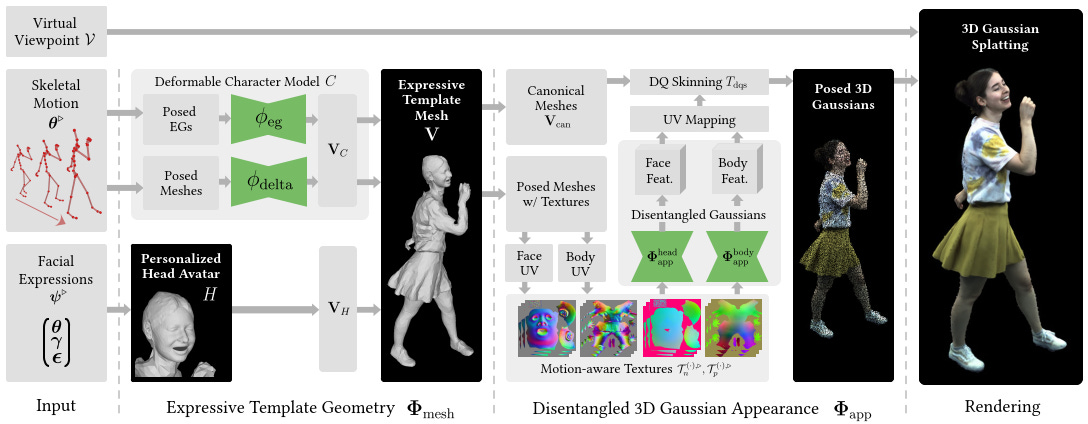
With recent advancements in neural rendering and motion capture algorithms, remarkable progress has been made in photorealistic human avatar modeling, unlocking immense potential for applications in virtual reality, augmented reality, remote communication, and industries such as gaming, film, and medicine. However, existing methods fail to provide complete, faithful, and expressive control over human avatars due to their entangled representation of facial expressions and body movements. In this work, we introduce Expressive Virtual Avatars (EVA), an actor-specific, fully controllable, and expressive human avatar framework that achieves high-fidelity, lifelike renderings in real time while enabling independent control of facial expressions, body movements, and hand gestures. Specifically, our approach designs the human avatar as a two-layer model: an expressive template geometry layer and a 3D Gaussian appearance layer. First, we present an expressive template tracking algorithm that leverages coarse-to-fine optimization to accurately recover body motions, facial expressions, and non-rigid deformation parameters from multi-view videos. Next, we propose a novel decoupled 3D Gaussian appearance model designed to effectively disentangle body and facial appearance. Unlike unified Gaussian estimation approaches, our method employs two specialized and independent modules to model the body and face separately. Experimental results demonstrate that EVA surpasses state-of-the-art methods in terms of rendering quality and expressiveness, validating its effectiveness in creating full-body avatars. This work represents a significant advancement towards fully drivable digital human models, enabling the creation of lifelike digital avatars that faithfully replicate human geometry and appearance.
Intentional Gesture: Deliver Your Intentions with Gestures for Speech
Pinxin Liu, Haiyang Liu, Luchuan Song, Chenliang Xu
University of Rochester
University of Tokyo
🚧 Project: https://andypinxinliu.github.io/Intentional-Gesture (not live yet)
📄 Paper: https://arxiv.org/pdf/2505.15197
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2505.15197

When humans speak, gestures help convey communicative intentions, such as adding emphasis or describing concepts. However, current co-speech gesture generation methods rely solely on superficial linguistic cues (e.g., speech audio or text transcripts), neglecting to understand and leverage the communicative intention that underpins human gestures. This results in outputs that are rhythmically synchronized with speech but are semantically shallow. To address this gap, we introduce Intentional-Gesture, a novel framework that casts gesture generation as an intention-reasoning task grounded in high-level communicative functions. First, we curate the InG dataset by augmenting BEAT-2 with gesture-intention annotations (i.e., text sentences summarizing intentions), which are automatically annotated using large vision-language models. Next, we introduce the Intentional Gesture Motion Tokenizer to leverage these intention annotations. It injects high-level communicative functions (\textit{e.g.}, intentions) into tokenized motion representations to enable intention-aware gesture synthesis that are both temporally aligned and semantically meaningful, achieving new state-of-the-art performance on the BEAT-2 benchmark. Our framework offers a modular foundation for expressive gesture generation in digital humans and embodied AI. Project Page: this https URL
AsynFusion: Towards Asynchronous Latent Consistency Models for Decoupled Whole-Body Audio-Driven Avatars
Tianbao Zhang, Jian Zhao, Yuer Li, Zheng Zhu, Ping Hu, Zhaoxin Fan, Wenjun Wu, Xuelong Li
🚧 Project: N/A
📄 Paper: https://arxiv.org/pdf/2505.15058
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2505.15058

Whole-body audio-driven avatar pose and expression generation is a critical task for creating lifelike digital humans and enhancing the capabilities of interactive virtual agents, with wide-ranging applications in virtual reality, digital entertainment, and remote communication. Existing approaches often generate audio-driven facial expressions and gestures independently, which introduces a significant limitation: the lack of seamless coordination between facial and gestural elements, resulting in less natural and cohesive animations. To address this limitation, we propose AsynFusion, a novel framework that leverages diffusion transformers to achieve harmonious expression and gesture synthesis. The proposed method is built upon a dual-branch DiT architecture, which enables the parallel generation of facial expressions and gestures. Within the model, we introduce a Cooperative Synchronization Module to facilitate bidirectional feature interaction between the two modalities, and an Asynchronous LCM Sampling strategy to reduce computational overhead while maintaining high-quality outputs. Extensive experiments demonstrate that AsynFusion achieves state-of-the-art performance in generating real-time, synchronized whole-body animations, consistently outperforming existing methods in both quantitative and qualitative evaluations.
FaceCrafter: Identity-Conditional Diffusion with Disentangled Control over Facial Pose, Expression, and Emotion
Kazuaki Mishima, Antoni Bigata Casademunt, Stavros Petridis, Maja Pantic, Kenji Suzuki
Imperial College London
🚧 Project: N/A
📄 Paper: https://arxiv.org/pdf/2505.15313
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2505.15313

Human facial images encode a rich spectrum of information, encompassing both stable identity-related traits and mutable attributes such as pose, expression, and emotion. While recent advances in image generation have enabled high-quality identity-conditional face synthesis, precise control over non-identity attributes remains challenging, and disentangling identity from these mutable factors is particularly difficult. To address these limitations, we propose a novel identity-conditional diffusion model that introduces two lightweight control modules designed to independently manipulate facial pose, expression, and emotion without compromising identity preservation. These modules are embedded within the cross-attention layers of the base diffusion model, enabling precise attribute control with minimal parameter overhead. Furthermore, our tailored training strategy, which leverages cross-attention between the identity feature and each non-identity control feature, encourages identity features to remain orthogonal to control signals, enhancing controllability and diversity. Quantitative and qualitative evaluations, along with perceptual user studies, demonstrate that our method surpasses existing approaches in terms of control accuracy over pose, expression, and emotion, while also improving generative diversity under identity-only conditioning.
Interspatial Attention for Efficient 4D Human Video Generation
Ruizhi Shao, Yinghao Xu, Yujun Shen, Ceyuan Yang, Yang Zheng, Changan Chen, Yebin Liu, Gordon Wetzstein
Tsinghua University
Stanford University
Ant Research
ByteDance
🚧 Project: https://dsaurus.github.io/isa4d/
📄 Paper: https://arxiv.org/pdf/2505.15800
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2505.15800

Generating photorealistic videos of digital humans in a controllable manner is crucial for a plethora of applications. Existing approaches either build on methods that employ template-based 3D representations or emerging video generation models but suffer from poor quality or limited consistency and identity preservation when generating individual or multiple digital humans. In this paper, we introduce a new interspatial attention (ISA) mechanism as a scalable building block for modern diffusion transformer (DiT)–based video generation models. ISA is a new type of cross attention that uses relative positional encodings tailored for the generation of human videos. Leveraging a custom-developed video variation autoencoder, we train a latent ISA-based diffusion model on a large corpus of video data. Our model achieves state-of-the-art performance for 4D human video synthesis, demonstrating remarkable motion consistency and identity preservation while providing precise control of the camera and body poses.
Adjacent Research
UPTor: Unified 3D Human Pose Dynamics and Trajectory Prediction for Human-Robot Interaction
UPTor introduces a unified framework that simultaneously predicts full-body 3D human poses and motion trajectories using a graph attention network and a non-autoregressive transformer, enhancing real-time human-robot interaction capabilities.
CineTechBench: A Benchmark for Cinematographic Technique Understanding and Generation
CineTechBench presents a manually annotated benchmark encompassing key cinematographic elements to evaluate and improve the understanding and generation of film techniques by multimodal large language models and video generation systems.
MonoSplat: Generalizable 3D Gaussian Splatting from Monocular Depth Foundation Models
MonoSplat leverages pre-trained monocular depth models to enhance 3D Gaussian Splatting, achieving real-time, high-fidelity rendering with improved generalization to novel scenes through a novel feature adaptation and prediction framework.
Colors Matter: AI-Driven Exploration of Human Feature Colors
This study introduces a machine learning framework that accurately classifies human features—such as skin tone, hair color, and vein-based undertones—using advanced imaging techniques and color space analyses, supporting applications in beauty tech and personalization.
Leveraging Generative AI Models to Explore Human Identity
This paper utilizes diffusion models to investigate the fluidity of human identity, demonstrating how variations in external inputs can lead to significant changes in generated facial images, thereby reflecting the dynamic nature of identity formation.
GT²-GS: Geometry-aware Texture Transfer for Gaussian Splatting
Paper
GT²-GS introduces a framework that enhances 3D Gaussian Splatting by incorporating geometry-aware texture transfer, employing a novel loss function and iterative strategy to achieve high-fidelity texture mapping aligned with scene geometry.
Constructing a 3D Town from a Single Image
3DTown presents a training-free approach to generate detailed 3D urban scenes from a single top-down image, utilizing region-based generation and spatial-aware 3D inpainting to ensure coherent geometry and texture without requiring multi-view data.