
Today in Character Technology - 4.30.25
Editing Gaussian Avatars, 3D Garment Reconstruction with sewing patterns, and validating photorealism.

Today we see a number of papers that aim to incrementally improve key areas of Gaussian Avatar Editing, Garment Reconstruction, and Facial Motion while listening.
We also see a paper aimed at assessing photorealism using human annotated data ranking realism.
Unfortunately none of todays researchers have shared their models, code, or even so much as a video! So while each presents some interesting concepts - I guess we have to take their word for it…
The more interesting paper of the batch was GarmentX, which aims to improve 3D Garment reconstruction by introducing sewing patterns into the data, which is a cool approach and would be beneficial to anyone looking to generate simulation-ready garments.
Cheers!
Creating Your Editable 3D Photorealistic Avatar with Tetrahedron-constrained Gaussian Splatting
Hanxi Liu, Yifang Men, Zhouhui Lian
Wangxuan Institute of Computer Technology, Peking University, China
Institute for Intelligent Computing, Alibaba Group
🚧Project: N/A
📄Paper: https://arxiv.org/pdf/2504.20403
💻Code: N/A
❌ArXiv: https://arxiv.org/abs/2504.20403
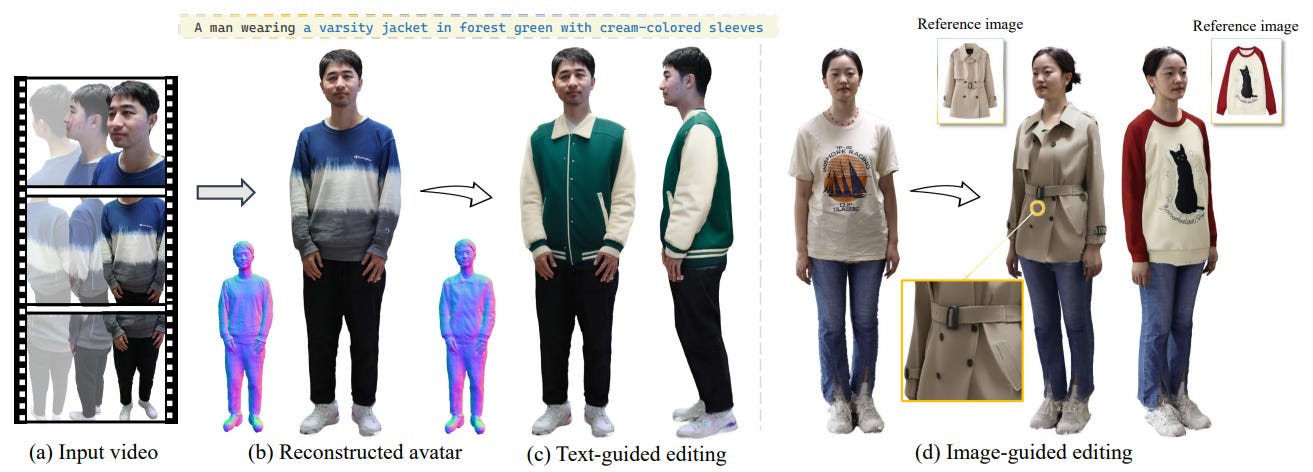
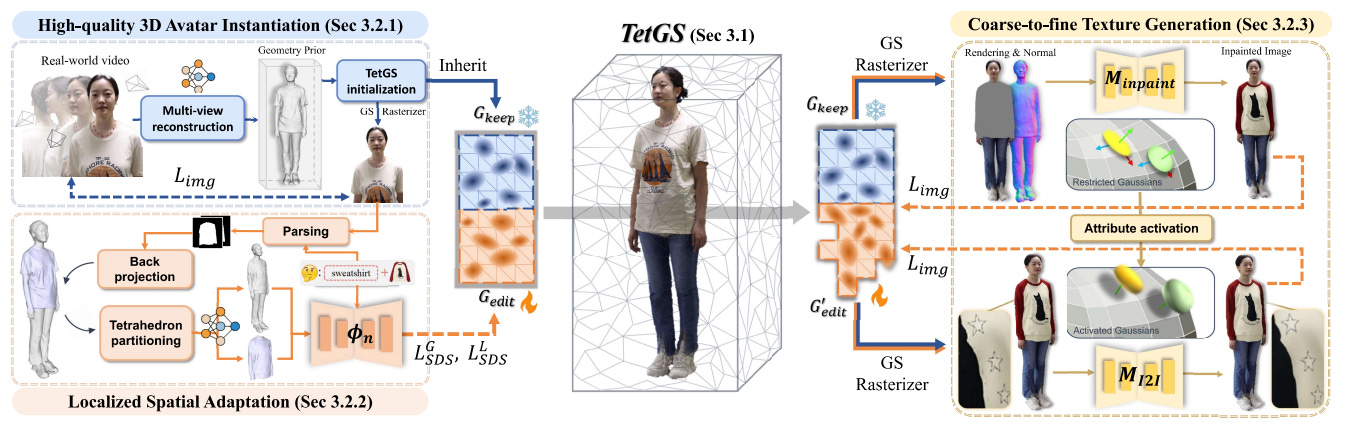
Personalized 3D avatar editing holds significant promise due to its user-friendliness and availability to applications such as AR/VR and virtual try-ons. Previous studies have explored the feasibility of 3D editing, but often struggle to generate visually pleasing results, possibly due to the unstable representation learning under mixed optimization of geometry and texture in complicated reconstructed scenarios. In this paper, we aim to provide an accessible solution for ordinary users to create their editable 3D avatars with precise region localization, geometric adaptability, and photorealistic renderings. To tackle this challenge, we introduce a meticulously designed framework that decouples the editing process into local spatial adaptation and realistic appearance learning, utilizing a hybrid Tetrahedron-constrained Gaussian Splatting (TetGS) as the underlying representation. TetGS combines the controllable explicit structure of tetrahedral grids with the high-precision rendering capabilities of 3D Gaussian Splatting and is optimized in a progressive manner comprising three stages: 3D avatar instantiation from real-world monocular videos to provide accurate priors for TetGS initialization; localized spatial adaptation with explicitly partitioned tetrahedrons to guide the redistribution of Gaussian kernels; and geometry-based appearance generation with a coarse-to-fine activation strategy. Both qualitative and quantitative experiments demonstrate the effectiveness and superiority of our approach in generating photorealistic 3D editable avatars.
Subjects:Graphics (cs.GR); Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2504.20403 [cs.GR]
GarmentX: Autoregressive Parametric Representations for High-Fidelity 3D Garment Generation
Jingfeng Guo, Jinnan Chen, Weikai Chen, Zhenyu Sun, Lanjiong Li, Baozhu Zhao, Lingting Zhu, Xin Wang, Qi Liu
South China University of Technology
National University of Singapore
LIGHTSPEED
The Hong Kong University of Science and Technology (Guangzhou)
The University of Hong Kong
🚧Project: N/A
📄Paper: https://arxiv.org/pdf/2504.20409
💻Code: N/A
❌ArXiv: https://arxiv.org/abs/2504.20409
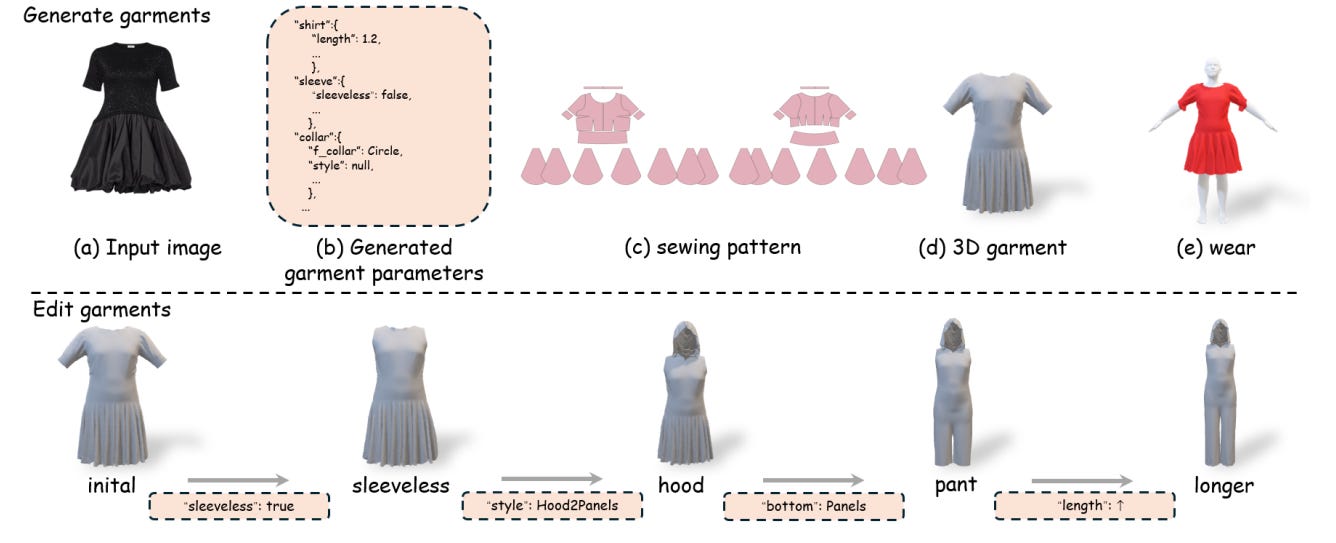
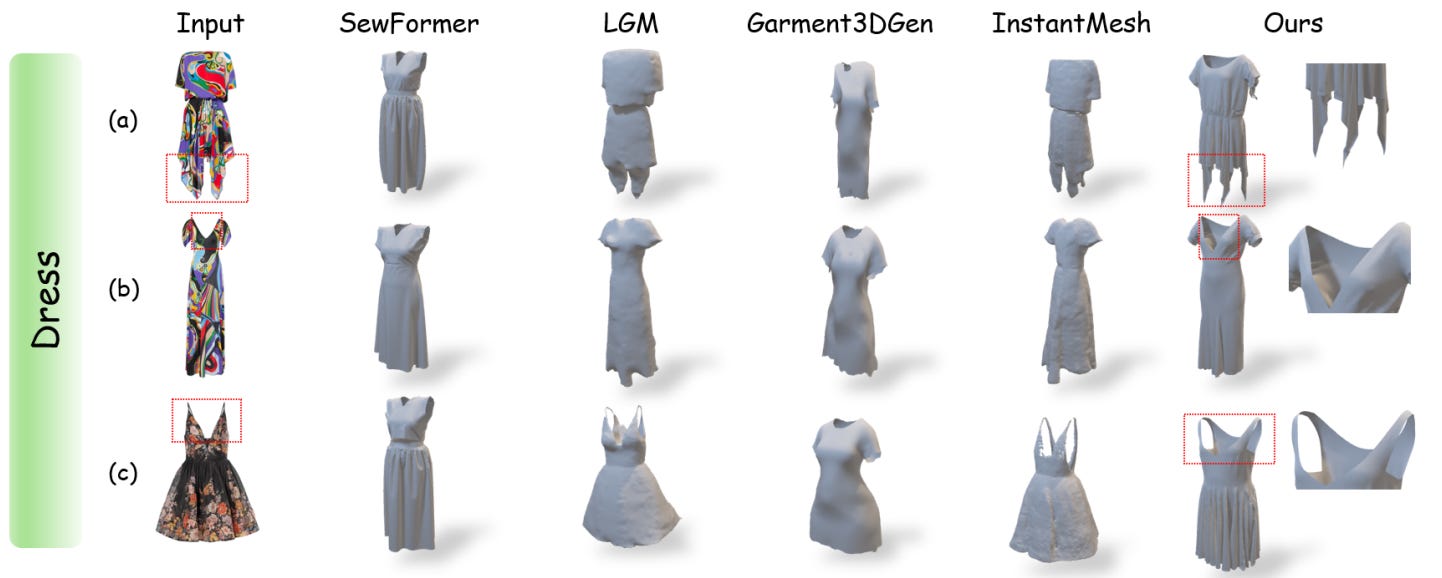
This work presents GarmentX, a novel framework for generating diverse, high-fidelity, and wearable 3D garments from a single input image. Traditional garment reconstruction methods directly predict 2D pattern edges and their connectivity, an overly unconstrained approach that often leads to severe self-intersections and physically implausible garment structures. In contrast, GarmentX introduces a structured and editable parametric representation compatible with GarmentCode, ensuring that the decoded sewing patterns always form valid, simulation-ready 3D garments while allowing for intuitive modifications of garment shape and style. To achieve this, we employ a masked autoregressive model that sequentially predicts garment parameters, leveraging autoregressive modeling for structured generation while mitigating inconsistencies in direct pattern prediction. Additionally, we introduce GarmentX dataset, a large-scale dataset of 378,682 garment parameter-image pairs, constructed through an automatic data generation pipeline that synthesizes diverse and high-quality garment images conditioned on parametric garment representations. Through integrating our method with GarmentX dataset, we achieve state-of-the-art performance in geometric fidelity and input image alignment, significantly outperforming prior approaches. We will release GarmentX dataset upon publication.
Subjects:Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2504.20409 [cs.CV]
Efficient Listener: Dyadic Facial Motion Synthesis via Action Diffusion
Zesheng Wang, Alexandre Bruckert, Patrick Le Callet, Guangtao Zhai
Shanghai Jiao Tong University
🚧Project: N/A
📄Paper: https://arxiv.org/pdf/2504.20685
💻Code: N/A
❌ArXiv: https://arxiv.org/abs/2504.20685
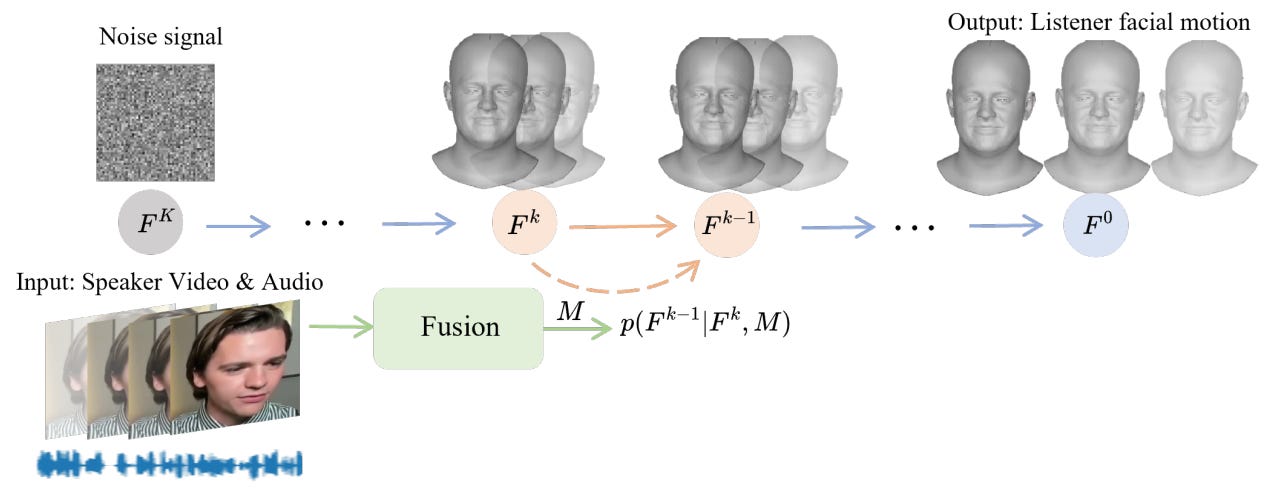
Generating realistic listener facial motions in dyadic conversations remains challenging due to the high-dimensional action space and temporal dependency requirements. Existing approaches usually consider extracting 3D Morphable Model (3DMM) coefficients and modeling in the 3DMM space. However, this makes the computational speed of the 3DMM a bottleneck, making it difficult to achieve real-time interactive responses. To tackle this problem, we propose Facial Action Diffusion (FAD), which introduces the diffusion methods from the field of image generation to achieve efficient facial action generation. We further build the Efficient Listener Network (ELNet) specially designed to accommodate both the visual and audio information of the speaker as input. Considering of FAD and ELNet, the proposed method learns effective listener facial motion representations and leads to improvements of performance over the state-of-the-art methods while reducing 99% computational time.
Subjects:Computer Vision and Pattern Recognition (cs.CV); Human-Computer Interaction (cs.HC)Cite as:arXiv:2504.20685 [cs.CV]
EfficientHuman: Efficient Training and Reconstruction of Moving Human using Articulated 2D Gaussian
Hao Tian, Rui Liu, Wen Shen, Yilong Hu, Zhihao Zheng, Xiaolin Qin
Chengdu Institute of Computer Applications, Chinese Academy of Sciences
Minzu University of China
University of Chinese Academy of Sciences
🚧Project: N/A
📄Paper: https://arxiv.org/pdf/2504.20607
💻Code: N/A
❌ArXiv: https://arxiv.org/abs/2504.20607

3D Gaussian Splatting (3DGS) has been recognized as a pioneering technique in scene reconstruction and novel view synthesis. Recent work on reconstructing the 3D human body using 3DGS attempts to leverage prior information on human pose to enhance rendering quality and improve training speed. However, it struggles to effectively fit dynamic surface planes due to multi-view inconsistency and redundant Gaussians. This inconsistency arises because Gaussian ellipsoids cannot accurately represent the surfaces of dynamic objects, which hinders the rapid reconstruction of the dynamic human body. Meanwhile, the prevalence of redundant Gaussians means that the training time of these works is still not ideal for quickly fitting a dynamic human body. To address these, we propose EfficientHuman, a model that quickly accomplishes the dynamic reconstruction of the human body using Articulated 2D Gaussian while ensuring high rendering quality. The key innovation involves encoding Gaussian splats as Articulated 2D Gaussian surfels in canonical space and then transforming them to pose space via Linear Blend Skinning (LBS) to achieve efficient pose transformations. Unlike 3D Gaussians, Articulated 2D Gaussian surfels can quickly conform to the dynamic human body while ensuring view-consistent geometries. Additionally, we introduce a pose calibration module and an LBS optimization module to achieve precise fitting of dynamic human poses, enhancing the model's performance. Extensive experiments on the ZJU-MoCap dataset demonstrate that EfficientHuman achieves rapid 3D dynamic human reconstruction in less than a minute on average, which is 20 seconds faster than the current state-of-the-art method, while also reducing the number of redundant Gaussians.
Comments:11 pages, 3 figuresSubjects:Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2504.20607 [cs.CV]
LMM4Gen3DHF: Benchmarking and Evaluating Multimodal 3D Human Face Generation with LMMs
Woo Yi Yang, Jiarui Wang, Sijing Wu, Huiyu Duan, Yuxin Zhu, Liu Yang, Kang Fu, Guangtao Zhai, Xiongkuo Min
Shanghai Jiao Tong University Shanghai, China
Institution Shanghai, China
🚧Project: N/A
📄Paper: https://arxiv.org/pdf/2504.20466
💻Code: N/A
❌ArXiv: https://arxiv.org/abs/2504.20466
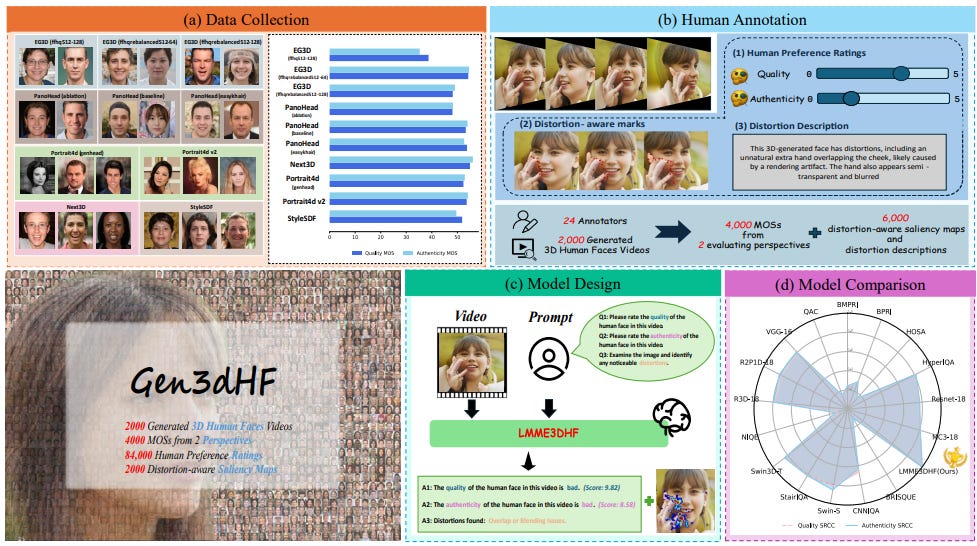
The rapid advancement in generative artificial intelligence have enabled the creation of 3D human faces (HFs) for applications including media production, virtual reality, security, healthcare, and game development, etc. However, assessing the quality and realism of these AI-generated 3D human faces remains a significant challenge due to the subjective nature of human perception and innate perceptual sensitivity to facial features. To this end, we conduct a comprehensive study on the quality assessment of AI-generated 3D human faces. We first introduce Gen3DHF, a large-scale benchmark comprising 2,000 videos of AI-Generated 3D Human Faces along with 4,000 Mean Opinion Scores (MOS) collected across two dimensions, i.e., quality and authenticity, 2,000 distortion-aware saliency maps and distortion descriptions. Based on Gen3DHF, we propose LMME3DHF, a Large Multimodal Model (LMM)-based metric for Evaluating 3DHF capable of quality and authenticity score prediction, distortion-aware visual question answering, and distortion-aware saliency prediction. Experimental results show that LMME3DHF achieves state-of-the-art performance, surpassing existing methods in both accurately predicting quality scores for AI-generated 3D human faces and effectively identifying distortion-aware salient regions and distortion types, while maintaining strong alignment with human perceptual judgments. Both the Gen3DHF database and the LMME3DHF will be released upon the publication.
Adjacent Research
Sparse2DGS: Geometry-Prioritized Gaussian Splatting for Surface Reconstruction from Sparse Views
Sparse2DGS combines Multi-View Stereo (MVS) with Gaussian Splatting and introduces geometric-prioritized enhancements to robustly reconstruct surfaces from very sparse views, outperforming NeRF-based methods in both accuracy and speed.
Why it matters for character tech: This enables high-quality surface reconstruction from just a few input images — ideal for fast scanning of characters or props in uncontrolled environments.
GSFeatLoc: Visual Localization Using Feature Correspondence on 3D Gaussian Splatting
GSFeatLoc localizes a query image within a 3D Gaussian Splatting scene using fast feature-based correspondence and PnP solving, reducing localization time by over 100× and maintaining high accuracy even with poor initial estimates.
Why it matters for character tech: This approach could empower real-time positioning of virtual characters or props within scanned environments, improving AR, mixed reality, or on-set tracking pipelines.