
Today in Character Technology - 4.29.25
Google, Snap & more present Real-time High Fidelity Gaussian Avatars, Improved Facial models from 3D Scans, Storyboards to 3D Animation & a comprehensive Survey of GenAI for Character Animation.

If you regularly monitor research in the Character Technology space, you’ll notice a pattern where much of the research solves or improves a specific problem-space such as monocular 3D Mesh reconstruction or albedo/specular texture recovery. Then there are projects that pull together many of those domain-specific improvements and produce an end-to-end pipeline for character creation.
You may also observe that rarely is any end-to-end paper at what we’d consider “production quality” or “production ready”. Sometimes this is due to the data used as input, and if you take the same model and provide higher quality input data you might expect to improve the output. Any other variety of factors from the output type to the cost of acquiring data may limit the quality of the final output. In addition - many organizations will publish their code (❤️❤️❤️) , and others keep it behind closed doors (👎👎👎) but at least illuminate their methods.
Add to that - virtually every “product” in this domain from Metahumans/Ziva to Wonder Dynamics are products built on the backs of this publicly available research.
I highlight this simply to help illustrate the frame of reference from which I feel we should evaluate the research. Oftentimes developers or tech artists will dismiss a category of research simply because the turn-key solution has not emerged.
I find it unlikely that we will see the emergence of a perfect, ubiquitous, turn-key, production ready, production quality, end-to-end technology for creating digital characters that look good from far away, close up, and in multiple lighting scenarios for some time. Even if something emerges that approximates this type of solution, it will likely be usurped within a few months. The days of monolith products like Maya that you can depend on for a decade are long gone.
The onus is on those of us working in this space to be able to quickly adapt, to assemble modular pieces that are easily swappable, augment it with our own data, and transform it into pipelines that suit the needs of the projects we’re supporting.
Today’s research presents of mixture of narrow and broad applications of character technology.
At the top, we see an end-to-end solution for Gaussian Human Avatars out of State Key Lab of Computer-aided Design & Computer Graphics & University of Utah.
Next up Google & ETH Zurich present us with a code-less (boo) paper proposes a solution to one of the key challenges of photogrammetry-based human scanning - disentangling skin from facial hair.
As if we didn’t get enough from those last ones - Google teams up with State Key Lab of CAD/CG to present us with a 3D-aware video diffusion model that aims to enhance multi-view consistency allowing diffusion-based avatars to work in AR/VR, among other applications.
Then we see two animation-centric papers - one focused on 2D Avatars and another focused on converting storyboards into 3D Animation (from Snap, et al).
Last but not least — Generative AI for Character Animation: A Comprehensive Survey of Techniques, Applications, and Future Directions — an excellent effort at cataloging some of the key research in the Character Technology space.
Real-time High-fidelity Gaussian Human Avatars with Position-based Interpolation of Spatially Distributed MLPs
Youyi Zhan, Tianjia Shao, Yin Yang, Kun Zhou
State Key Lab of CAD&CG, Zhejiang University
University of Utah
🚧Project: https://gapszju.github.io/mmlphuman/
💻Code: https://github.com/1231234zhan/mmlphuman
📄Paper: https://gapszju.github.io/mmlphuman/static/paper/zhan2025realtime.pdf
❌ArXiv: https://arxiv.org/abs/2504.12909
Many works have succeeded in reconstructing Gaussian human avatars from multi-view videos. However, they either struggle to capture pose-dependent appearance details with a single MLP, or rely on a computationally intensive neural network to reconstruct high-fidelity appearance but with rendering performance degraded to non-real-time. We propose a novel Gaussian human avatar representation that can reconstruct high-fidelity pose-dependence appearance with details and meanwhile can be rendered in real time. Our Gaussian avatar is empowered by spatially distributed MLPs which are explicitly located on different positions on human body. The parameters stored in each Gaussian are obtained by interpolating from the outputs of its nearby MLPs based on their distances. To avoid undesired smooth Gaussian property changing during interpolation, for each Gaussian we define a set of Gaussian offset basis, and a linear combination of basis represents the Gaussian property offsets relative to the neutral properties. Then we propose to let the MLPs output a set of coefficients corresponding to the basis. In this way, although Gaussian coefficients are derived from interpolation and change smoothly, the Gaussian offset basis is learned freely without constraints. The smoothly varying coefficients combined with freely learned basis can still produce distinctly different Gaussian property offsets, allowing the ability to learn high-frequency spatial signals. We further use control points to constrain the Gaussians distributed on a surface layer rather than allowing them to be irregularly distributed inside the body, to help the human avatar generalize better when animated under novel poses. Compared to the state-of-the-art method, our method achieves better appearance quality with finer details while the rendering speed is significantly faster under novel views and novel poses.
Comments:CVPR 2025. Project page this https URL . Code this https URLSubjects:Graphics (cs.GR); Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2504.12909 [cs.GR]
Pixels2Points: Fusing 2D and 3D Features for Facial Skin Segmentation
Victoria Yue Chen, Daoye Wang, Stephan Garbin, Sebastian Winberg, Timo Bolkart, Thabo Beeler
Google
ETH Zürich
🚧Project: N/A
💻Code: N/A
📄Paper: https://arxiv.org/pdf/2504.19718
❌ArXiv: https://arxiv.org/abs/2504.19718
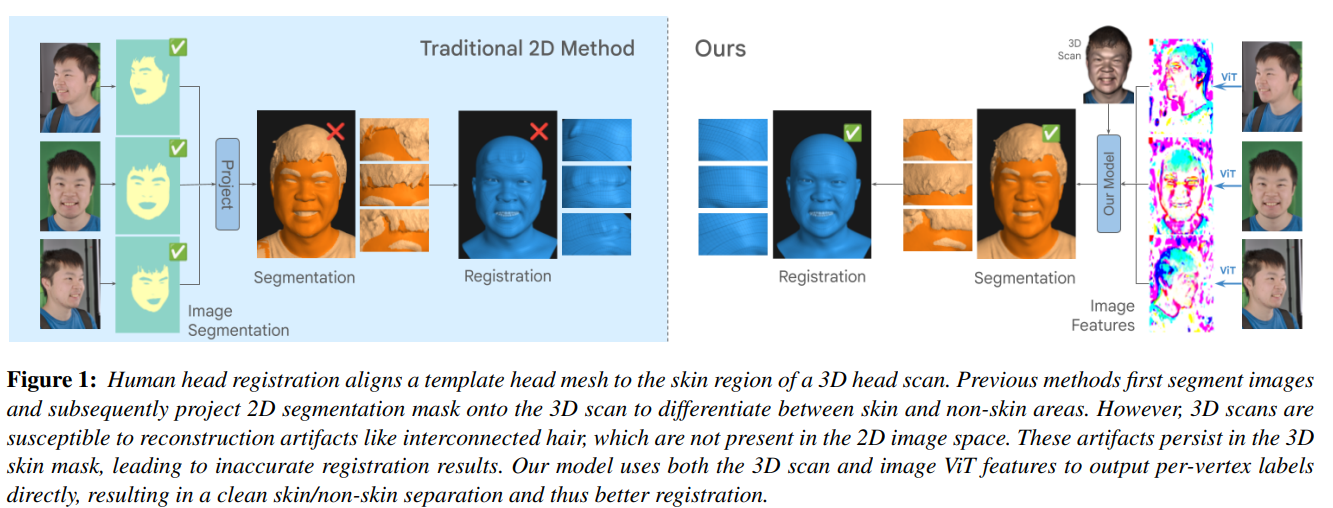
Face registration deforms a template mesh to closely fit a 3D face scan, the quality of which commonly degrades in non-skin regions (e.g., hair, beard, accessories), because the optimized template-to-scan distance pulls the template mesh towards the noisy scan surface. Improving registration quality requires a clean separation of skin and non-skin regions on the scan mesh. Existing image-based (2D) or scan-based (3D) segmentation methods however perform poorly. Image-based segmentation outputs multi-view inconsistent masks, and they cannot account for scan inaccuracies or scan-image misalignment, while scan-based methods suffer from lower spatial resolution compared to images. In this work, we introduce a novel method that accurately separates skin from non-skin geometry on 3D human head scans. For this, our method extracts features from multi-view images using a frozen image foundation model and aggregates these features in 3D. These lifted 2D features are then fused with 3D geometric features extracted from the scan mesh, to then predict a segmentation mask directly on the scan mesh. We show that our segmentations improve the registration accuracy over pure 2D or 3D segmentation methods by 8.89% and 14.3%, respectively. Although trained only on synthetic data, our model generalizes well to real data.
Comments:4 pages, 4 figures, to be published in Eurographics 2025 as a short paperSubjects:Graphics (cs.GR); Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2504.19718 [cs.GR]
IM-Portrait: Learning 3D-aware Video Diffusion for PhotorealisticTalking Heads from Monocular Videos
Yuan Li, Ziqian Bai, Feitong Tan, Zhaopeng Cui, Sean Fanello, Yinda Zhang
State Key Lab of CAD&CG, Zhejiang University
Google
🚧Project: https://y-u-a-n-l-i.github.io/projects/IM-Portrait/
💻Code: N/A
📄Paper: https://arxiv.org/pdf/2504.19165
❌ArXiv: https://arxiv.org/abs/2504.19165

We propose a novel 3D-aware diffusion-based method for generating photorealistic talking head videos directly from a single identity image and explicit control signals (e.g., expressions). Our method generates Multiplane Images (MPIs) that ensure geometric consistency, making them ideal for immersive viewing experiences like binocular videos for VR headsets. Unlike existing methods that often require a separate stage or joint optimization to reconstruct a 3D representation (such as NeRF or 3D Gaussians), our approach directly generates the final output through a single denoising process, eliminating the need for post-processing steps to render novel views efficiently. To effectively learn from monocular videos, we introduce a training mechanism that reconstructs the output MPI randomly in either the target or the reference camera space. This approach enables the model to simultaneously learn sharp image details and underlying 3D information. Extensive experiments demonstrate the effectiveness of our method, which achieves competitive avatar quality and novel-view rendering capabilities, even without explicit 3D reconstruction or high-quality multi-view training data.
Comments:CVPR2025; project page: this https URLSubjects:Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2504.19165 [cs.CV]
AnimateAnywhere: Rouse the Background in Human Image Animation
Xiaoyu Liu, Mingshuai Yao, Yabo Zhang, Xianhui Lin, Peiran Ren, Xiaoming Li, Ming Liu, Wangmeng Zuo
Harbin Institute of Technology, Harbin, China
Nanyang Technological University, Singapore
🚧Project: https://animateanywhere.github.io/
💻Code: https://github.com/liuxiaoyu1104/AnimateAnywhere
📄Paper: https://arxiv.org/pdf/2504.19834
❌ArXiv: https://arxiv.org/abs/2504.19834
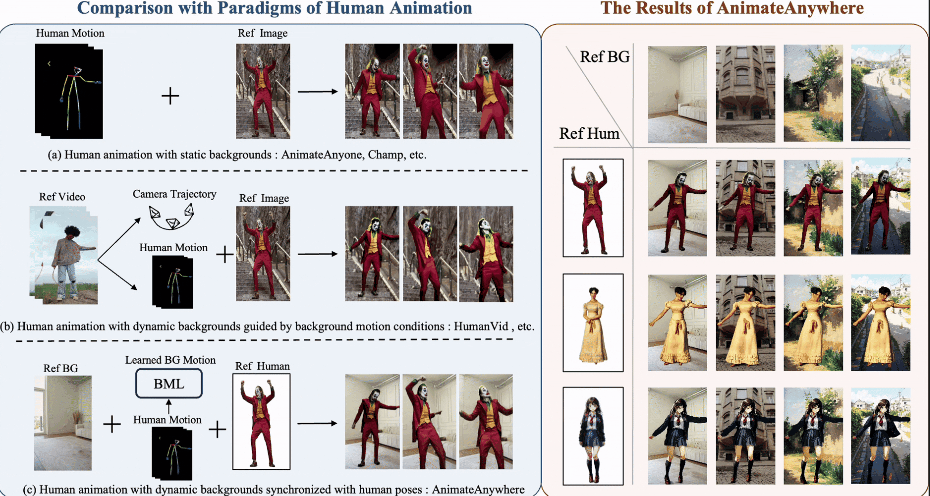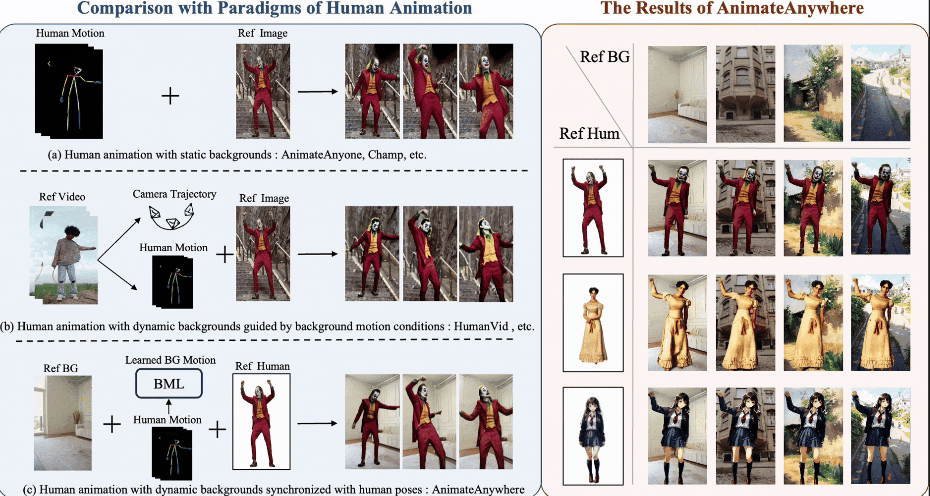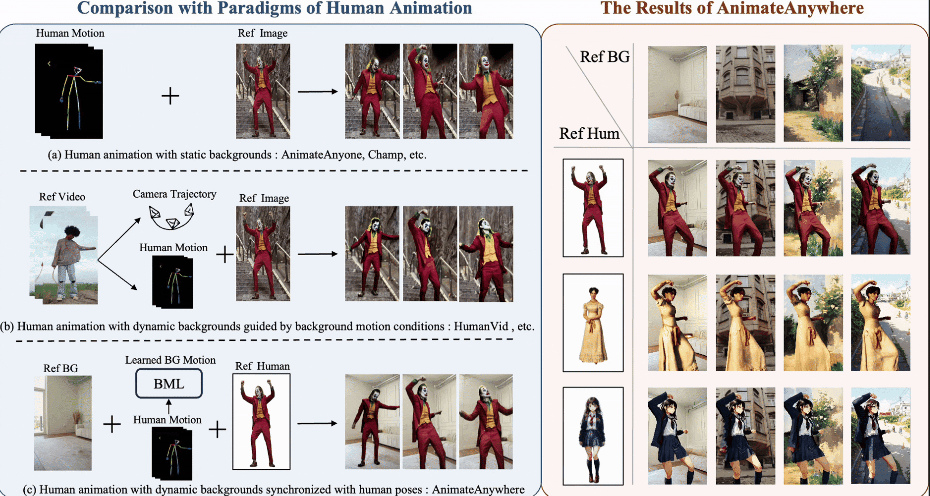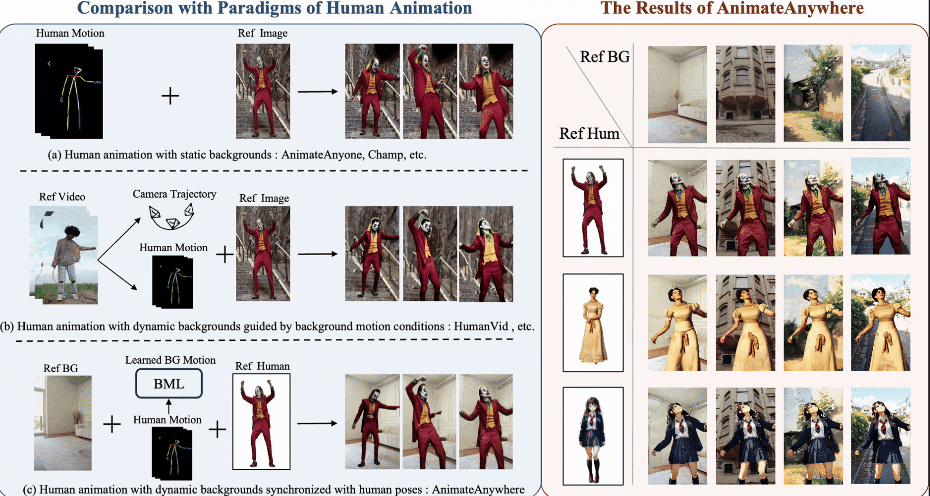
Human image animation aims to generate human videos of given characters and backgrounds that adhere to the desired pose sequence. However, existing methods focus more on human actions while neglecting the generation of background, which typically leads to static results or inharmonious movements. The community has explored camera pose-guided animation tasks, yet preparing the camera trajectory is impractical for most entertainment applications and ordinary users. As a remedy, we present an AnimateAnywhere framework, rousing the background in human image animation without requirements on camera trajectories. In particular, based on our key insight that the movement of the human body often reflects the motion of the background, we introduce a background motion learner (BML) to learn background motions from human pose sequences. To encourage the model to learn more accurate cross-frame correspondences, we further deploy an epipolar constraint on the 3D attention map. Specifically, the mask used to suppress geometrically unreasonable attention is carefully constructed by combining an epipolar mask and the current 3D attention map. Extensive experiments demonstrate that our AnimateAnywhere effectively learns the background motion from human pose sequences, achieving state-of-the-art performance in generating human animation results with vivid and realistic backgrounds. The source code and model will be available at this https URL.
Subjects:Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2504.19834 [cs.CV]
Sketch2Anim: Towards Transferring Sketch Storyboards into 3D Animation
Lei Zhong, Chuan Guo, Yiming Xie, Jiawei Wang, Changjian Li
University of Edinburgh, United Kingdom
Snap Inc., United States
Northeastern University, United States
🚧Project: https://zhongleilz.github.io/Sketch2Anim/
💻Code: https://zhongleilz.github.io/Sketch2Anim/
📄Paper: https://arxiv.org/pdf/2504.19189
❌ArXiv: https://arxiv.org/abs/2504.19189

Storyboarding is widely used for creating 3D animations. Animators use the 2D sketches in storyboards as references to craft the desired 3D animations through a trial-and-error process. The traditional approach requires exceptional expertise and is both labor-intensive and time-consuming. Consequently, there is a high demand for automated methods that can directly translate 2D storyboard sketches into 3D animations. This task is under-explored to date and inspired by the significant advancements of motion diffusion models, we propose to address it from the perspective of conditional motion synthesis. We thus present Sketch2Anim, composed of two key modules for sketch constraint understanding and motion generation. Specifically, due to the large domain gap between the 2D sketch and 3D motion, instead of directly conditioning on 2D inputs, we design a 3D conditional motion generator that simultaneously leverages 3D keyposes, joint trajectories, and action words, to achieve precise and fine-grained motion control. Then, we invent a neural mapper dedicated to aligning user-provided 2D sketches with their corresponding 3D keyposes and trajectories in a shared embedding space, enabling, for the first time, direct 2D control of motion generation. Our approach successfully transfers storyboards into high-quality 3D motions and inherently supports direct 3D animation editing, thanks to the flexibility of our multi-conditional motion generator. Comprehensive experiments and evaluations, and a user perceptual study demonstrate the effectiveness of our approach.
Comments:Project page: this https URLSubjects:Graphics (cs.GR); Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2504.19189 [cs.GR]
Survey
Generative AI for Character Animation: A Comprehensive Survey of Techniques, Applications, and Future Directions
Mohammad Mahdi Abootorabi, Omid Ghahroodi, Pardis Sadat Zahraei, Hossein Behzadasl, Alireza Mirrokni, Mobina Salimipanah, Arash Rasouli, Bahar Behzadipour, Sara Azarnoush, Benyamin Maleki, Erfan Sadraiye, Kiarash Kiani Feriz, Mahdi Teymouri Nahad, Ali Moghadasi, Abolfazl Eshagh Abianeh, Nizi Nazar, Hamid R. Rabiee, Mahdieh Soleymani Baghshah, Meisam Ahmadi, Ehsaneddin Asgari
🚧Project: https://github.com/llm-lab-org/Generative-AI-for-Character-Animation-Survey
📄Paper: https://arxiv.org/pdf/2504.19056
❌ArXiv: https://arxiv.org/abs/2504.19056

Generative AI is reshaping art, gaming, and most notably animation. Recent breakthroughs in foundation and diffusion models have reduced the time and cost of producing animated content. Characters are central animation components, involving motion, emotions, gestures, and facial expressions. The pace and breadth of advances in recent months make it difficult to maintain a coherent view of the field, motivating the need for an integrative review. Unlike earlier overviews that treat avatars, gestures, or facial animation in isolation, this survey offers a single, comprehensive perspective on all the main generative AI applications for character animation. We begin by examining the state-of-the-art in facial animation, expression rendering, image synthesis, avatar creation, gesture modeling, motion synthesis, object generation, and texture synthesis. We highlight leading research, practical deployments, commonly used datasets, and emerging trends for each area. To support newcomers, we also provide a comprehensive background section that introduces foundational models and evaluation metrics, equipping readers with the knowledge needed to enter the field. We discuss open challenges and map future research directions, providing a roadmap to advance AI-driven character-animation technologies. This survey is intended as a resource for researchers and developers entering the field of generative AI animation or adjacent fields. Resources are available at: this https URL.
Comments:50 main pages, 30 pages appendix, 21 figures, 8 tables, GitHub Repository: this https URLSubjects:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG); Multimedia (cs.MM)Cite as:arXiv:2504.19056 [cs.CV]
Adjacent Research
As always, below is emerging research in a variety of categories which may ultimately find their way into improving character technology.
HumMorph: Generalized Dynamic Human Neural Fields from Few Views
HumMorph enables fast free-viewpoint rendering of dynamic humans with explicit pose control, using just one or two input views and handling noisy pose estimates without requiring precise multi-camera setups.
A Decade of You Only Look Once (YOLO) for Object Detection
This review covers the evolution of the YOLO object detection framework over the last decade, highlighting major versions, trends, application areas, and future directions.
Point2Quad: Generating Quad Meshes from Point Clouds via Face Prediction
Point2Quad proposes the first learning-based method for creating quad-only meshes directly from point clouds, combining geometric and topological features to ensure quad quality and mesh coherence.
Audio-Driven Talking Face Video Generation with Joint Uncertainty Learning
This paper introduces JULNet, a new approach for audio-driven talking face generation that models visual uncertainty alongside lip-sync accuracy, improving fidelity and robustness across diverse conditions.
CompleteMe: Reference-based Human Image Completion
CompleteMe presents a reference-guided inpainting method that better captures fine-grained clothing details and accessories by focusing attention on corresponding regions of the reference images.
TransparentGS: Fast Inverse Rendering of Transparent Objects with Gaussians
TransparentGS introduces a fast method to reconstruct and render transparent objects by extending 3D Gaussian Splatting with light field probes and a deferred refraction model.
CLR-Wire: Towards Continuous Latent Representations for 3D Curve Wireframe Generation
CLR-Wire introduces a continuous latent space approach for generating complex 3D curve-based wireframes, unifying geometry and topology into a single learned representation.