
Today in Character Technology - 4.28.25
Anatomy Shaping and Twins Negotiating, Adding emotion to 2D Talking Heads, Co-Speech Gestures

Picking up where the 4.22.25 post left off, we see another entry in the monocular 3D avatar reconstruction category with Unify3D, which is today’s most pertinent entry into the Character Technology category.
Moving on we see DICE-Talk, an effort to disentangle identity and emotion in 2D Talking head generation addressing a key aspect of control in talking head generation. The talking-head category has seen quite a lot of development over the last year, with Microsoft’s VASA-1 sparking enormous interest. While it was not by any means first in talking-head generation, it was the first paper that turned heads towards the real possibilities - proceeded within months by products like Hedra and Heygen.
SSD-Poser aims to infer full body poses from limited AR/VR inputs.
And last, CoCoGesture reappeared on the radar after it was redacted for further exploration - however it’s a good read none-the-less with a large data-set designed to aid in inference of body gesture from speech (or co-speech 3d gestures).
Enjoy!
Unify3D: An Augmented Holistic End-to-end Monocular 3D Human Reconstruction via Anatomy Shaping and Twins Negotiating
Nanjie Yao, Gangjian Zhang, Wenhao Shen, Jian Shu, Hao Wang
Nangyang Technological University
HKUST(GZ)
🚧Project: https://e2e3dgsrecon.github.io/e2e3dgsrecon/
💻Code: N/A
📄Paper: https://arxiv.org/pdf/2504.18215
❌ArXiv: https://arxiv.org/abs/2504.18215

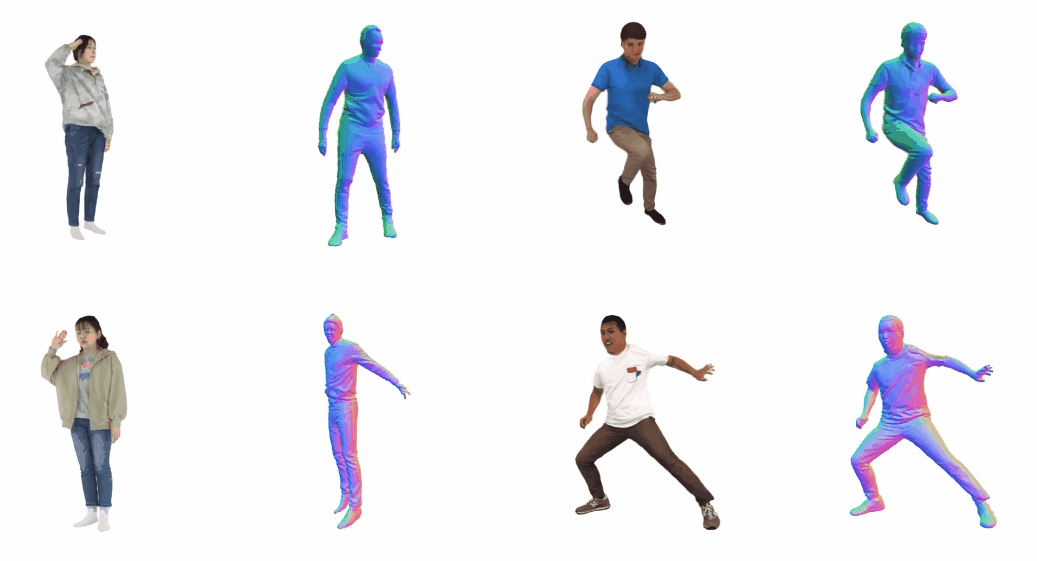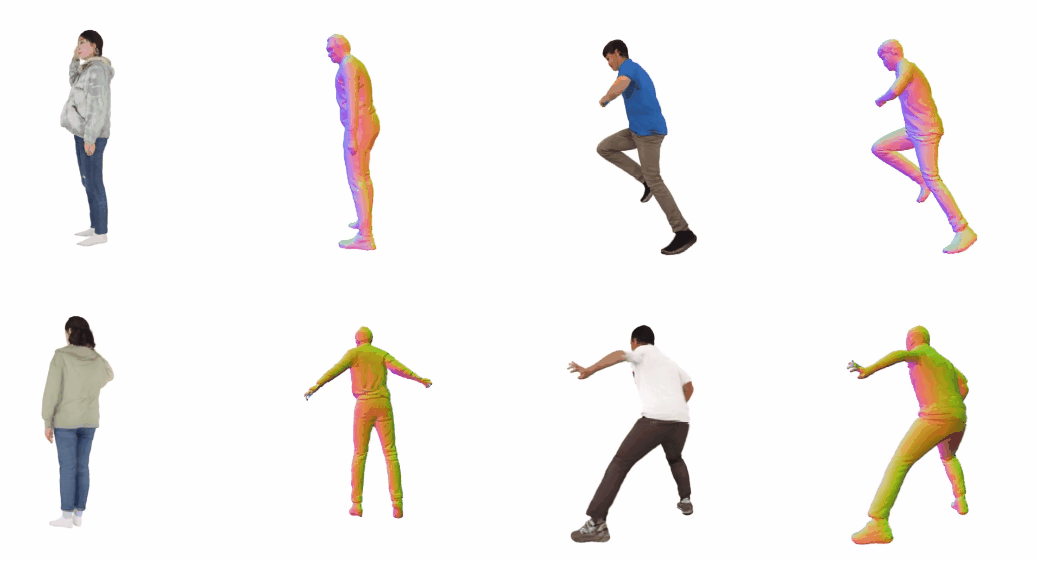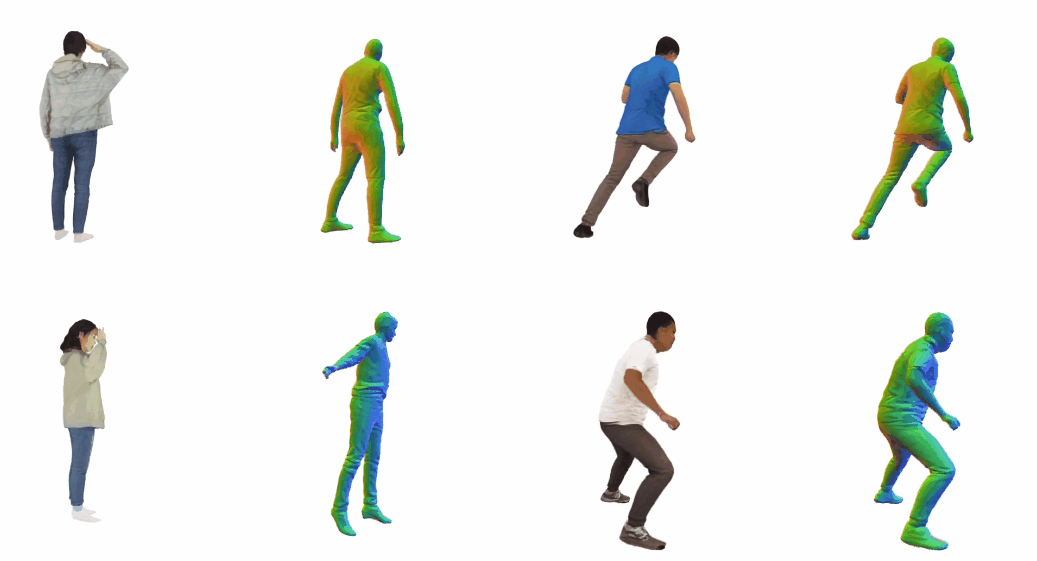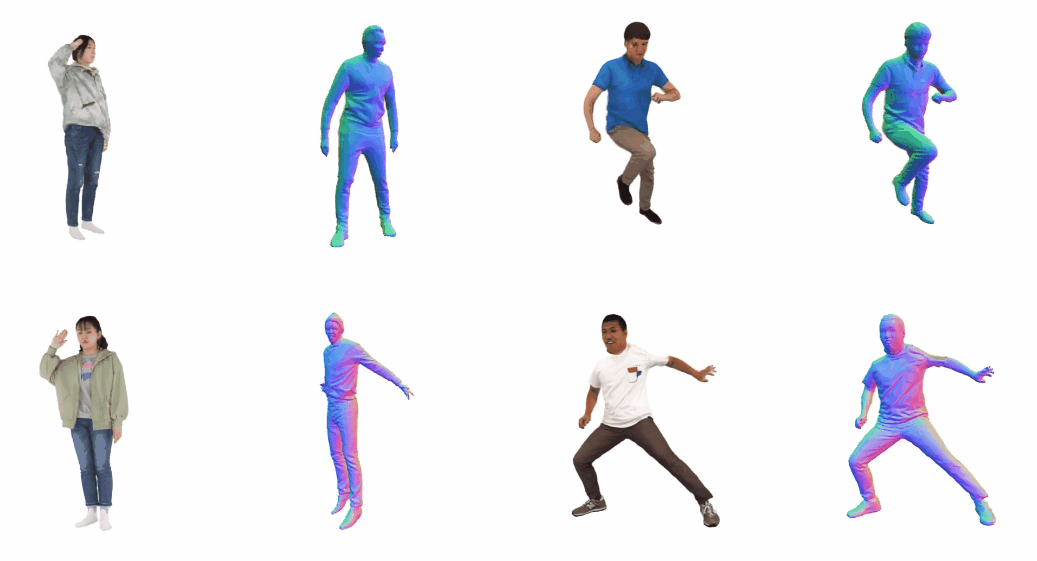
Monocular 3D clothed human reconstruction aims to create a complete 3D avatar from a single image. To tackle the human geometry lacking in one RGB image, current methods typically resort to a preceding model for an explicit geometric representation. For the reconstruction itself, focus is on modeling both it and the input image. This routine is constrained by the preceding model, and overlooks the integrity of the reconstruction task. To address this, this paper introduces a novel paradigm that treats human reconstruction as a holistic process, utilizing an end-to-end network for direct prediction from 2D image to 3D avatar, eliminating any explicit intermediate geometry display. Based on this, we further propose a novel reconstruction framework consisting of two core components: the Anatomy Shaping Extraction module, which captures implicit shape features taking into account the specialty of human anatomy, and the Twins Negotiating Reconstruction U-Net, which enhances reconstruction through feature interaction between two U-Nets of different modalities. Moreover, we propose a Comic Data Augmentation strategy and construct 15k+ 3D human scans to bolster model performance in more complex case input. Extensive experiments on two test sets and many in-the-wild cases show the superiority of our method over SOTA methods. Our demos can be found in : this https URL.
Subjects:Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2504.18215 [cs.CV]
Disentangle Identity, Cooperate Emotion: Correlation-Aware Emotional Talking Portrait Generation
Weipeng Tan, Chuming Lin, Chengming Xu, FeiFan Xu, Xiaobin Hu, Xiaozhong Ji, Junwei Zhu, Chengjie Wang, Yanwei Fu
Fudan University
Youtu Lab, Tencent, China
🚧Project: https://github.com/toto222/DICE-Talk
💻Code: https://github.com/toto222/DICE-Talk
📄Paper: https://arxiv.org/pdf/2504.18087
❌ArXiv: https://arxiv.org/abs/2504.18087
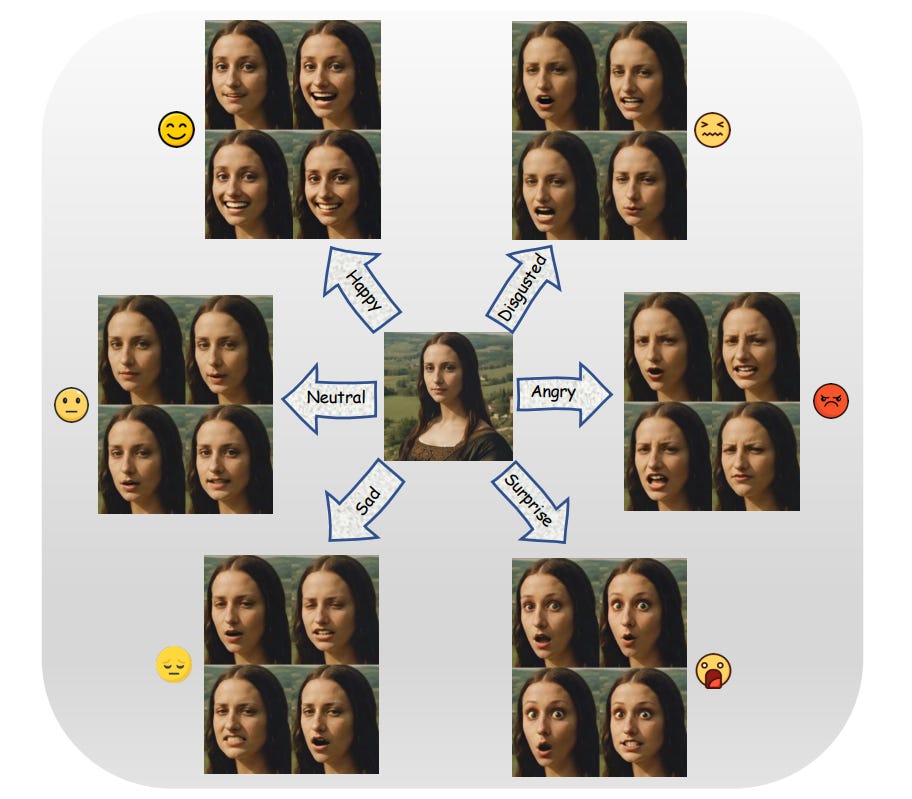
Recent advances in Talking Head Generation (THG) have achieved impressive lip synchronization and visual quality through diffusion models; yet existing methods struggle to generate emotionally expressive portraits while preserving speaker identity. We identify three critical limitations in current emotional talking head generation: insufficient utilization of audio's inherent emotional cues, identity leakage in emotion representations, and isolated learning of emotion correlations. To address these challenges, we propose a novel framework dubbed as DICE-Talk, following the idea of disentangling identity with emotion, and then cooperating emotions with similar characteristics. First, we develop a disentangled emotion embedder that jointly models audio-visual emotional cues through cross-modal attention, representing emotions as identity-agnostic Gaussian distributions. Second, we introduce a correlation-enhanced emotion conditioning module with learnable Emotion Banks that explicitly capture inter-emotion relationships through vector quantization and attention-based feature aggregation. Third, we design an emotion discrimination objective that enforces affective consistency during the diffusion process through latent-space classification. Extensive experiments on MEAD and HDTF datasets demonstrate our method's superiority, outperforming state-of-the-art approaches in emotion accuracy while maintaining competitive lip-sync performance. Qualitative results and user studies further confirm our method's ability to generate identity-preserving portraits with rich, correlated emotional expressions that naturally adapt to unseen identities.
Comments:arXiv admin note: text overlap with arXiv:2409.03270Subjects:Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2504.18087 [cs.CV]
SSD-Poser: Avatar Pose Estimation with State Space Duality from Sparse Observations
Shuting Zhao, Linxin Bai, Liangjing Shao, Ye Zhang, Xinrong Chen
Academy for Engineering & Technology, Fudan University Shanghai, China
College of Vocational and Technical Teacher Education, Shanghai
Polytechnic University Shanghai, China
🚧Project: N/A
💻Code: N/A
📄Paper: https://arxiv.org/pdf/2504.18332
❌ArXiv: https://arxiv.org/abs/2504.18332
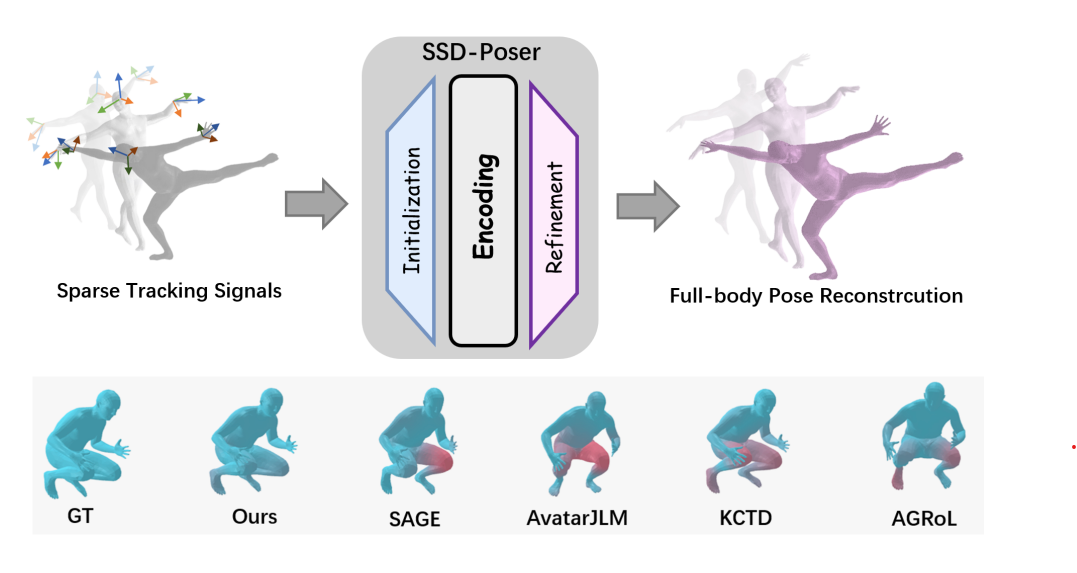
The growing applications of AR/VR increase the demand for real-time full-body pose estimation from Head-Mounted Displays (HMDs). Although HMDs provide joint signals from the head and hands, reconstructing a full-body pose remains challenging due to the unconstrained lower body. Recent advancements often rely on conventional neural networks and generative models to improve performance in this task, such as Transformers and diffusion models. However, these approaches struggle to strike a balance between achieving precise pose reconstruction and maintaining fast inference speed. To overcome these challenges, a lightweight and efficient model, SSD-Poser, is designed for robust full-body motion estimation from sparse observations. SSD-Poser incorporates a well-designed hybrid encoder, State Space Attention Encoders, to adapt the state space duality to complex motion poses and enable real-time realistic pose reconstruction. Moreover, a Frequency-Aware Decoder is introduced to mitigate jitter caused by variable-frequency motion signals, remarkably enhancing the motion smoothness. Comprehensive experiments on the AMASS dataset demonstrate that SSD-Poser achieves exceptional accuracy and computational efficiency, showing outstanding inference efficiency compared to state-of-the-art methods.
Comments:9 pages, 6 figures, conference ICMR 2025Subjects:Computer Vision and Pattern Recognition (cs.CV); Human-Computer Interaction (cs.HC)MSC classes:68U05Cite as:arXiv:2504.18332 [cs.CV]
CoCoGesture: Toward Coherent Co-speech 3D Gesture Generation in the Wild
Xingqun Qi, Hengyuan Zhang, Yatian Wang, Jiahao Pan, Chen Liu, Peng Li, Xiaowei Chi, Mengfei Li, Wei Xue, Shanghang Zhang, Wenhan Luo, Qifeng Liu, Yike Guo
The Hong Kong University of Science and Technology
Peking University
University of Queensland
NOTE: This paper was published in 2024, however a recent withdrawal put it back on the radar this morning. Per the withdrawal:
After the submission of the paper, we realized that the study still has room for expansion. In order to make the research findings more profound and comprehensive, we have decided to withdraw the paper so that we can conduct further research and expansion
🚧Project: https://mattie-e.github.io/GES-X/
🤗Model/Data: https://mattie-e.github.io/GES-X/
📄Paper: https://arxiv.org/pdf/2405.16874v2
❌ArXiv: https://arxiv.org/abs/2405.16874v2
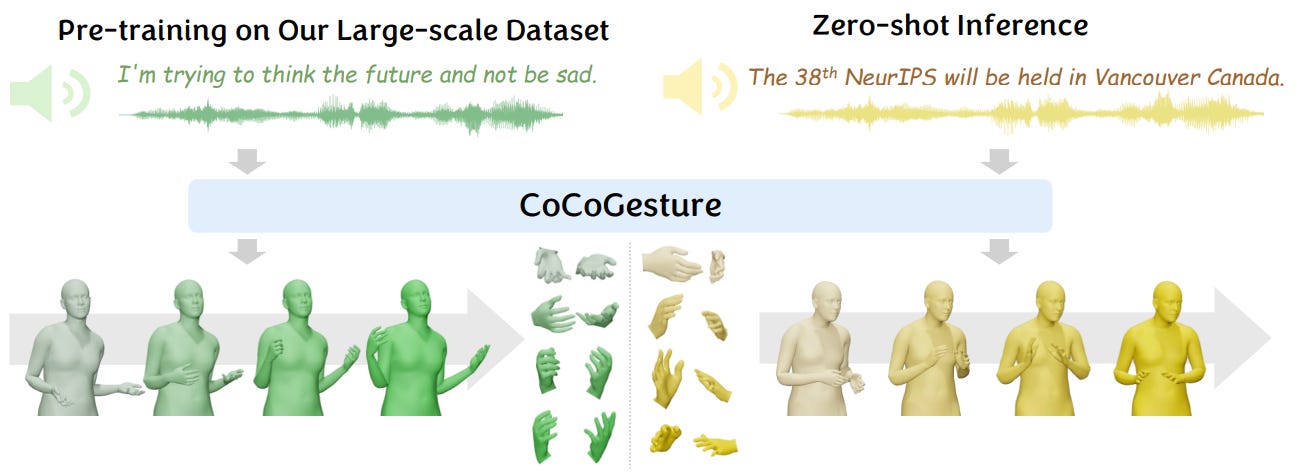

Deriving co-speech 3D gestures has seen tremendous progress in virtual avatar animation. Yet, the existing methods often produce stiff and unreasonable gestures with unseen human speech inputs due to the limited 3D speech-gesture data. In this paper, we propose CoCoGesture, a novel framework enabling vivid and diverse gesture synthesis from unseen human speech prompts. Our key insight is built upon the custom-designed pretrain-fintune training paradigm. At the pretraining stage, we aim to formulate a large generalizable gesture diffusion model by learning the abundant postures manifold. Therefore, to alleviate the scarcity of 3D data, we first construct a large-scale co-speech 3D gesture dataset containing more than 40M meshed posture instances across 4.3K speakers, dubbed GES-X. Then, we scale up the large unconditional diffusion model to 1B parameters and pre-train it to be our gesture experts. At the finetune stage, we present the audio ControlNet that incorporates the human voice as condition prompts to guide the gesture generation. Here, we construct the audio ControlNet through a trainable copy of our pre-trained diffusion model. Moreover, we design a novel Mixture-of-Gesture-Experts (MoGE) block to adaptively fuse the audio embedding from the human speech and the gesture features from the pre-trained gesture experts with a routing mechanism. Such an effective manner ensures audio embedding is temporal coordinated with motion features while preserving the vivid and diverse gesture generation. Extensive experiments demonstrate that our proposed CoCoGesture outperforms the state-of-the-art methods on the zero-shot speech-to-gesture generation. The dataset will be publicly available at: this https URL
Comments:The dataset will be released as soon as possibleSubjects:Computer Vision and Pattern Recognition (cs.CV)Cite as:arXiv:2405.16874 [cs.CV]
Adjacent Research
Object Learning and Robust 3D Reconstruction
This thesis explores architectures and training methods for unsupervised object segmentation in 2D and 3D, introducing techniques like FlowCapsules and transient object masking to improve 3D modeling from casual captures.
STP4D: Spatio-Temporal-Prompt Consistent Modeling for Text-to-4D Gaussian Splatting
Yunze Deng, Haijun Xiong, Bin Feng, Xinggang Wang, Wenyu Liu
STP4D introduces a new framework combining spatio-temporal modeling and prompt consistency for fast, high-fidelity 4D Gaussian Splatting generation from text descriptions.
ActionArt: Advancing Multimodal Large Models for Fine-Grained Human-Centric Video Understanding
Yi-Xing Peng, Qize Yang, Yu-Ming Tang, Shenghao Fu, Kun-Yu Lin, Xihan Wei, Wei-Shi Zheng
ActionArt presents a detailed dataset and new proxy tasks designed to improve fine-grained multimodal understanding of human actions and poses in video, reducing reliance on costly manual annotations.
RGS-DR: Reflective Gaussian Surfels with Deferred Rendering for Shiny Objects
Georgios Kouros, Minye Wu, Tinne Tuytelaars
RGS-DR introduces a deferred rendering method using Gaussian surfels that captures glossy and reflective materials accurately, enabling high-quality inverse rendering and flexible scene relighting.