
Today in Character Technology - 10/23/25
ICCV Spotlight: Text to Hair, Physically Reactive and Interactive Motor Model for Avatar Learning. Then, new papers on improving motion synthesis and pose estimation.

Starting today off with a spotlight on a few more interesting ICCV papers not previously covered here, and then onto today’s releases which are largely in the domain of 3D pose estimation and motion synthesis.
ICCV 2025 Spotlight
https://iccv.thecvf.com/Conferences/2025/AcceptedPapers
StrandHead: Text to Hair-Disentangled 3D Head Avatars Using Human-Centric Priors
Xiaokun Sun, Zeyu Cai, Ying Tai, Jian Yang, Zhenyu Zhang
Nanjing University
🚧 Project: https://xiaokunsun.github.io/StrandHead.github.io/
📄 Paper: https://arxiv.org/pdf/2412.11586
❌ ArXiv: https://arxiv.org/abs/2412.11586
💻 Code: https://github.com/XiaokunSun/StrandHead

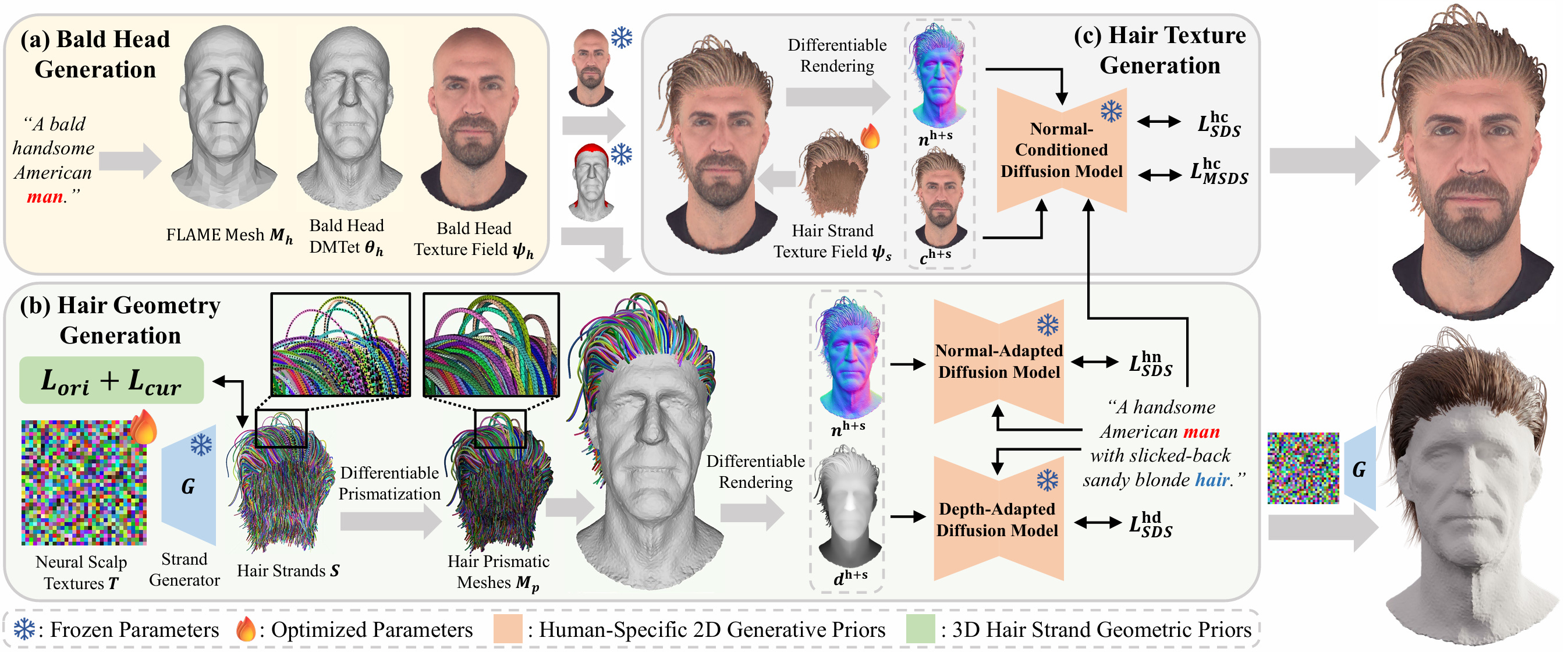
While haircut indicates distinct personality, existing avatar generation methods fail to model practical hair due to the data limitation or entangled representation. We propose StrandHead, a novel text-driven method capable of generating 3D hair strands and disentangled head avatars with strand-level attributes. Instead of using large-scale hair-text paired data for supervision, we demonstrate that realistic hair strands can be generated from prompts by distilling 2D generative models pre-trained on human mesh data. To this end, we propose a meshing approach guided by strand geometry to guarantee the gradient flow from the distillation objective to the neural strand representation. The optimization is then regularized by statistically significant haircut features, leading to stable updating of strands against unreasonable drifting. These employed 2D/3D human-centric priors contribute to text-aligned and realistic 3D strand generation. Extensive experiments show that StrandHead achieves the state-of-the-art performance on text to strand generation and disentangled 3D head avatar modeling. The generated 3D hair can be applied on avatars for strand-level editing, as well as implemented in the graphics engine for physical simulation or other applications.
PRIMAL: Physically Reactive and Interactive Motor Model for Avatar Learning
Yan Zhang, Yao Feng, Alpár Cseke, Nitin Saini, Nathan Bajandas, Nicolas Heron, Michael J. Black
Meshcapade
Max Planck Institute for Intelligent Systems, Tubingen
Stanford University
🚧 Project: https://yz-cnsdqz.github.io/eigenmotion/PRIMAL/
📄 Paper: https://arxiv.org/pdf/2503.17544
❌ ArXiv: https://arxiv.org/abs/2503.17544
💻 Code: https://github.com/yz-cnsdqz/primal-release
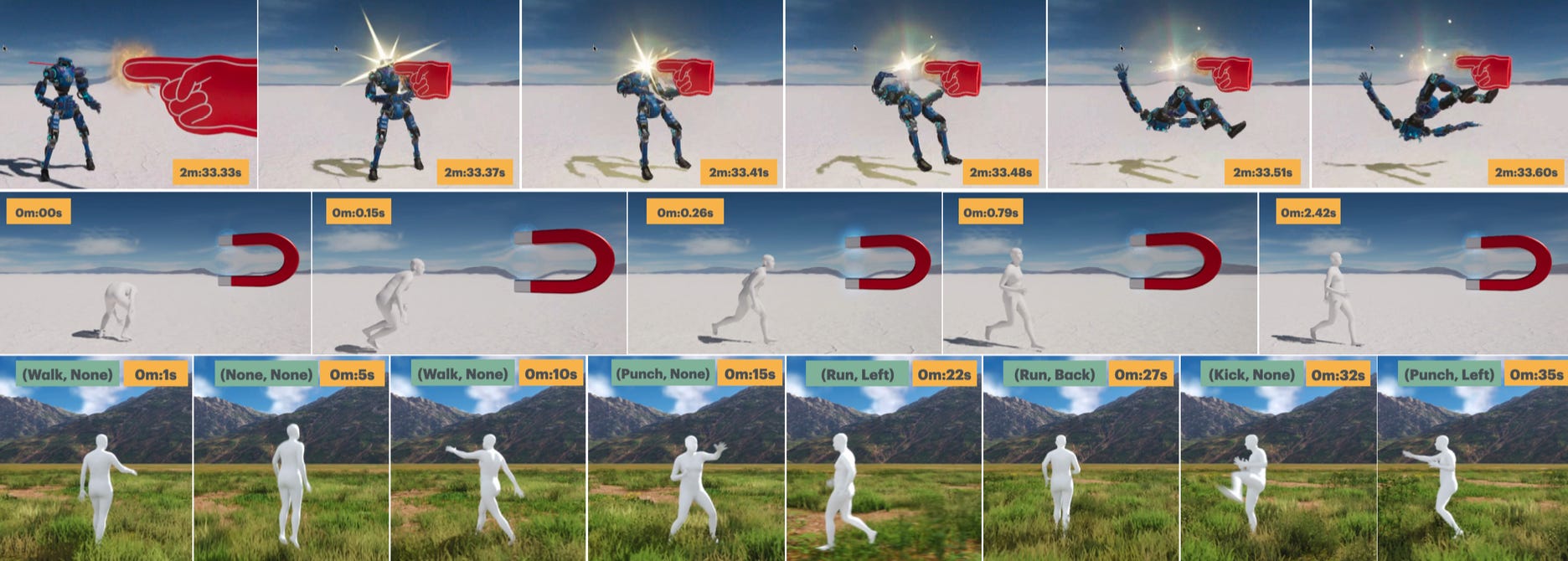

We formulate the motor system of an interactive avatar as a generative motion model that can drive the body to move through 3D space in a perpetual, realistic, controllable, and responsive manner. Although human motion generation has been extensively studied, many existing methods lack the responsiveness and realism of real human movements. Inspired by recent advances in foundation models, we propose PRIMAL, which is learned with a two-stage paradigm. In the pretraining stage, the model learns body movements from a large number of sub-second motion segments, providing a generative foundation from which more complex motions are built. This training is fully unsupervised without annotations. Given a single-frame initial state during inference, the pretrained model not only generates unbounded, realistic, and controllable motion, but also enables the avatar to be responsive to induced impulses in real time. In the adaptation phase, we employ a novel ControlNet-like adaptor to fine-tune the base model efficiently, adapting it to new tasks such as few-shot personalized action generation and spatial target reaching. Evaluations show that our proposed method outperforms state-of-the-art baselines. We leverage the model to create a real-time character animation system in Unreal Engine that feels highly responsive and natural. Code, models, and more results are available at: this https URL
Today - 10.23.25
OmniMotion-X: Versatile Multimodal Whole-Body Motion Generation
Guowei Xu, Yuxuan Bian, Ailing Zeng, Mingyi Shi, Shaoli Huang, Wen Li, Lixin Duan, Qiang Xu
University of Electronic Science and Technology of China
The Chinese University of Hong Kong
The University of Hong Kong
Tencent
🚧 Project: N/A
📄 Paper: https://arxiv.org/pdf/2510.19789
❌ ArXiv: https://arxiv.org/abs/2510.19789
💻 Code/Dataset: https://github.com/GuoweiXu368/OmniMotion-X
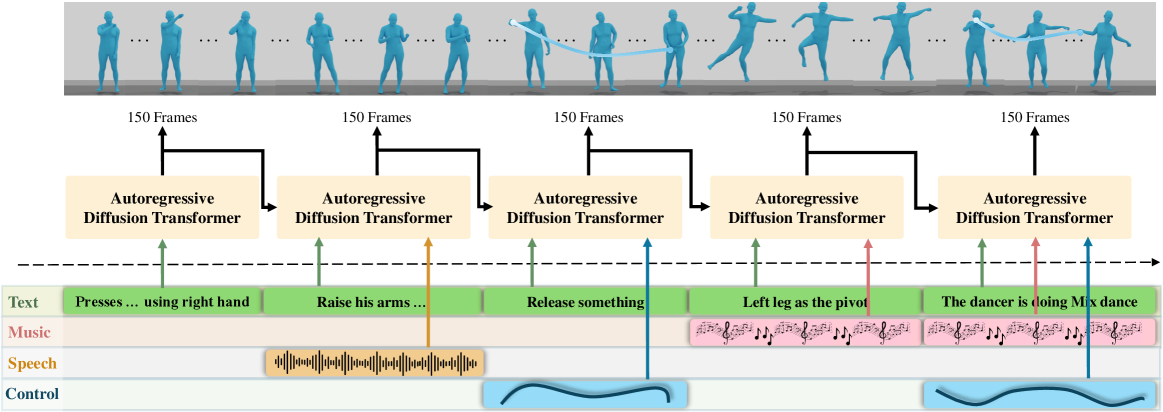
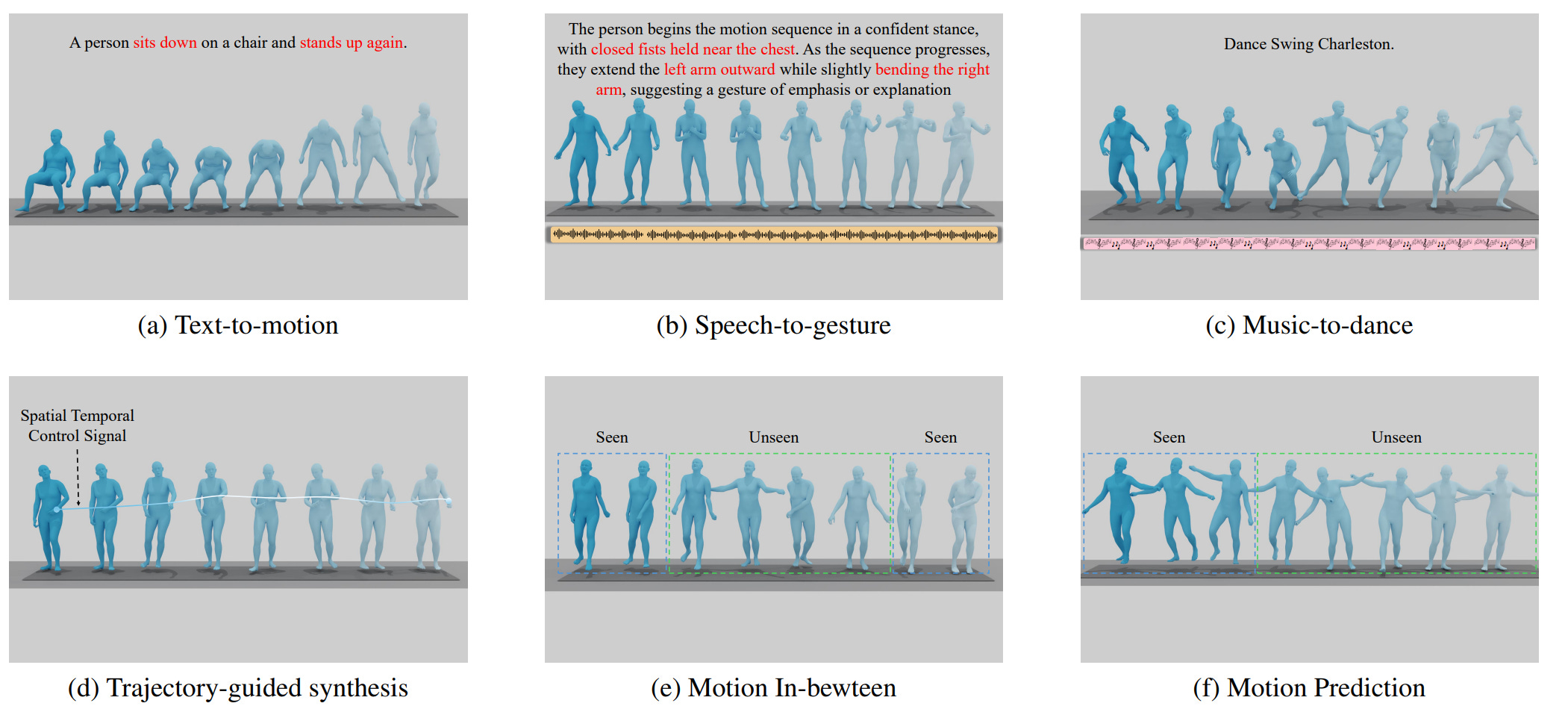
This paper introduces OmniMotion-X, a versatile multimodal framework for whole-body human motion generation, leveraging an autoregressive diffusion transformer in a unified sequence-to-sequence manner. OmniMotion-X efficiently supports diverse multimodal tasks, including text-to-motion, music-to-dance, speech-to-gesture, and global spatial-temporal control scenarios (e.g., motion prediction, in-betweening, completion, and joint/trajectory-guided synthesis), as well as flexible combinations of these tasks. Specifically, we propose the use of reference motion as a novel conditioning signal, substantially enhancing the consistency of generated content, style, and temporal dynamics crucial for realistic animations. To handle multimodal conflicts, we introduce a progressive weak-to-strong mixed-condition training strategy. To enable high-quality multimodal training, we construct OmniMoCap-X, the largest unified multimodal motion dataset to date, integrating 28 publicly available MoCap sources across 10 distinct tasks, standardized to the SMPL-X format at 30 fps. To ensure detailed and consistent annotations, we render sequences into videos and use GPT-4o to automatically generate structured and hierarchical captions, capturing both low-level actions and high-level semantics. Extensive experimental evaluations confirm that OmniMotion-X significantly surpasses existing methods, demonstrating state-of-the-art performance across multiple multimodal tasks and enabling the interactive generation of realistic, coherent, and controllable long-duration motions.
PRGCN: A Graph Memory Network for Cross-Sequence Pattern Reuse in 3D Human Pose Estimation
Zhuoyang Xie, Yibo Zhao, Hui Huang, Riwei Wang, Zan Gao
School of Data Science and Artificial Intelligence, Wenzhou University of Technology
College of Computer Science and Artificial Intelligence, Wenzhou University
Shandong Artificial Intelligence Institute, Qilu University of Technology (Shandong Academy of Sciences)
the Key Laboratory of Computer Vision and System, Ministry of Education, Tianjin University of Technology
🚧 Project: N/A
📄 Paper: https://arxiv.org/pdf/2510.19475
❌ ArXiv: https://arxiv.org/abs/2510.19475
💻 Code: N/A
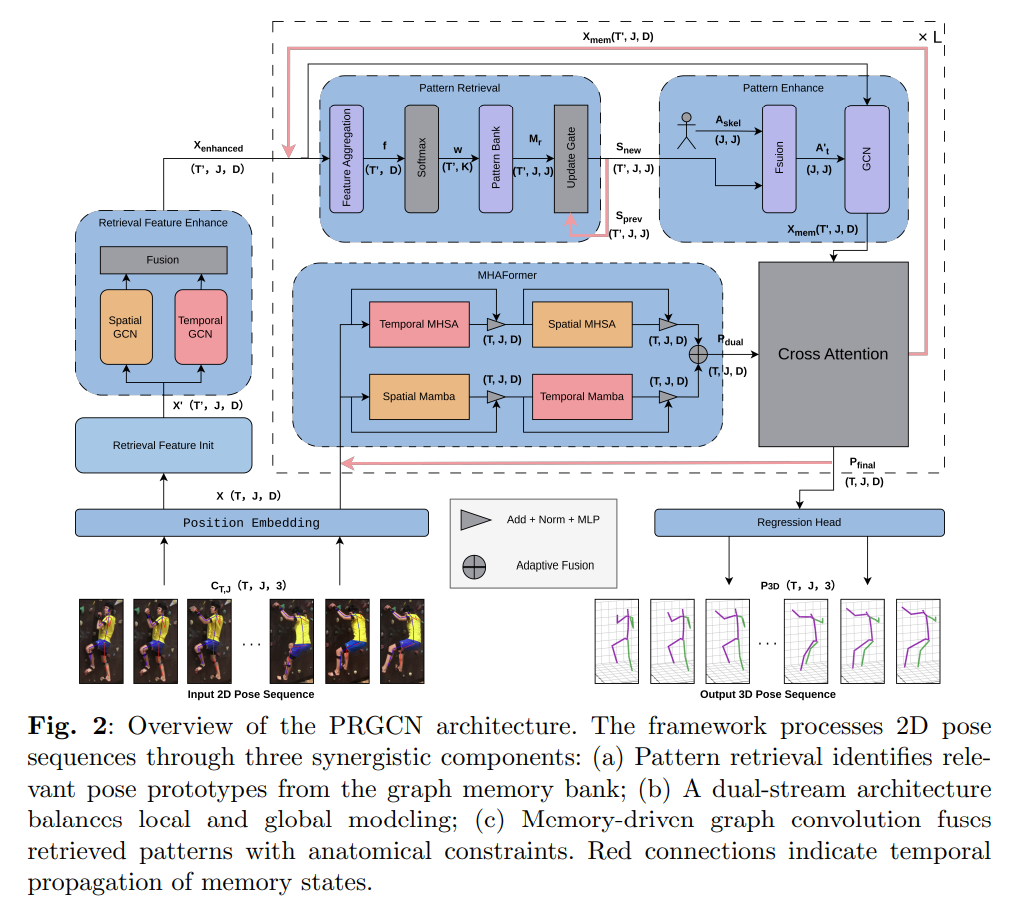
Monocular 3D human pose estimation remains a fundamentally ill-posed inverse problem due to the inherent depth ambiguity in 2D-to-3D lifting. While contemporary video-based methods leverage temporal context to enhance spatial reasoning, they operate under a critical paradigm limitation: processing each sequence in isolation, thereby failing to exploit the strong structural regularities and repetitive motion patterns that pervade human movement across sequences. This work introduces the Pattern Reuse Graph Convolutional Network (PRGCN), a novel framework that formalizes pose estimation as a problem of pattern retrieval and adaptation. At its core, PRGCN features a graph memory bank that learns and stores a compact set of pose prototypes, encoded as relational graphs, which are dynamically retrieved via an attention mechanism to provide structured priors. These priors are adaptively fused with hard-coded anatomical constraints through a memory-driven graph convolution, ensuring geometrical plausibility. To underpin this retrieval process with robust spatiotemporal features, we design a dual-stream hybrid architecture that synergistically combines the linear-complexity, local temporal modeling of Mamba-based state-space models with the global relational capacity of self-attention. Extensive evaluations on Human3.6M and MPI-INF-3DHP benchmarks demonstrate that PRGCN establishes a new state-of-the-art, achieving an MPJPE of 37.1mm and 13.4mm, respectively, while exhibiting enhanced cross-domain generalization capability. Our work posits that the long-overlooked mechanism of cross-sequence pattern reuse is pivotal to advancing the field, shifting the paradigm from per-sequence optimization towards cumulative knowledge learning.
UniHPR: Unified Human Pose Representation via Singular Value Contrastive Learning
Zhongyu Jiang, Wenhao Chai, Lei Li, Zhuoran Zhou, Cheng-Yen Yang, Jenq-Neng Hwang
University of Washington
University of Copenhagen
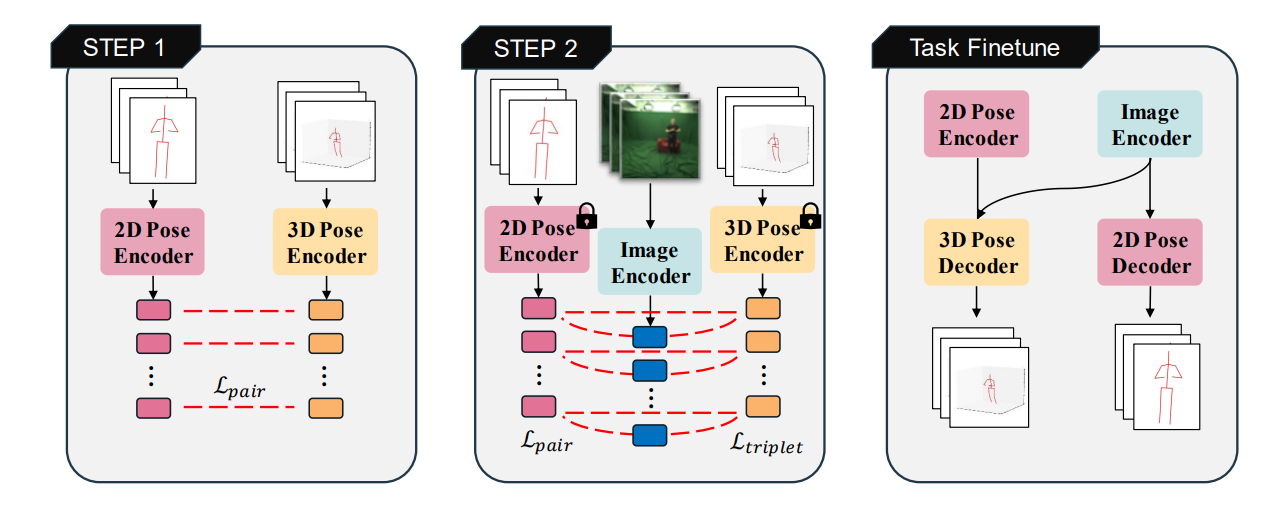
In recent years, there has been a growing interest in developing effective alignment pipelines to generate unified representations from different modalities for multi-modal fusion and generation. As an important component of Human-Centric applications, Human Pose representations are critical in many downstream tasks, such as Human Pose Estimation, Action Recognition, Human-Computer Interaction, Object tracking, etc. Human Pose representations or embeddings can be extracted from images, 2D keypoints, 3D skeletons, mesh models, and lots of other modalities. Yet, there are limited instances where the correlation among all of those representations has been clearly researched using a contrastive paradigm. In this paper, we propose UniHPR, a unified Human Pose Representation learning pipeline, which aligns Human Pose embeddings from images, 2D and 3D human poses. To align more than two data representations at the same time, we propose a novel singular value-based contrastive learning loss, which better aligns different modalities and further boosts performance. To evaluate the effectiveness of the aligned representation, we choose 2D and 3D Human Pose Estimation (HPE) as our evaluation tasks. In our evaluation, with a simple 3D human pose decoder, UniHPR achieves remarkable performance metrics: MPJPE 49.9mm on the Human3.6M dataset and PA-MPJPE 51.6mm on the 3DPW dataset with cross-domain evaluation. Meanwhile, we are able to achieve 2D and 3D pose retrieval with our unified human pose representations in Human3.6M dataset, where the retrieval error is 9.24mm in MPJPE.