
Today in Character Technology - 10.22.25

Today was a light day in terms of papers released. With this week being the 2025 International Conference on Computer Vision, I’m including a few of the accepted papers that haven’t yet been covered here.
Cheers!
Latent-Info and Low-Dimensional Learning for Human Mesh Recovery and Parallel Optimization
Xiang Zhang, Suping Wu, Sheng Yang
School of Information Engineering Ningxia University YinChuan, China
🚧 Project: N/A
📄 Paper: https://arxiv.org/abs/2510.18267
❌ ArXiv: https://arxiv.org/abs/2510.18267
💻 Code: N/A
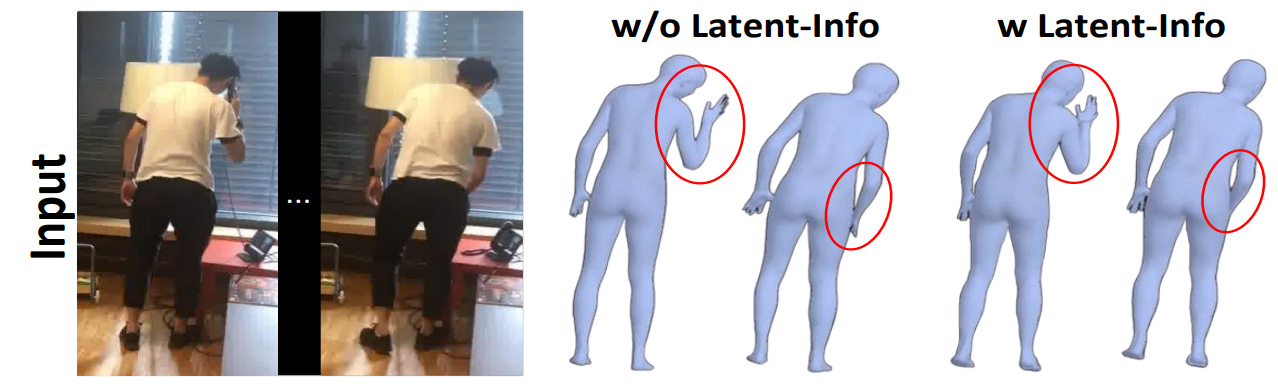
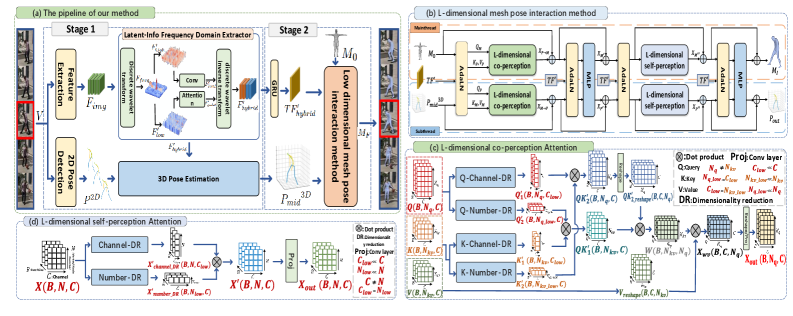
Existing 3D human mesh recovery methods often fail to fully exploit the latent information (e.g., human motion, shape alignment), leading to issues with limb misalignment and insufficient local details in the reconstructed human mesh (especially in complex scenes). Furthermore, the performance improvement gained by modelling mesh vertices and pose node interactions using attention mechanisms comes at a high computational cost. To address these issues, we propose a two-stage network for human mesh recovery based on latent information and low dimensional learning. Specifically, the first stage of the network fully excavates global (e.g., the overall shape alignment) and local (e.g., textures, detail) information from the low and high-frequency components of image features and aggregates this information into a hybrid latent frequency domain feature. This strategy effectively extracts latent information. Subsequently, utilizing extracted hybrid latent frequency domain features collaborates to enhance 2D poses to 3D learning. In the second stage, with the assistance of hybrid latent features, we model the interaction learning between the rough 3D human mesh template and the 3D pose, optimizing the pose and shape of the human mesh. Unlike existing mesh pose interaction methods, we design a low-dimensional mesh pose interaction method through dimensionality reduction and parallel optimization that significantly reduces computational costs without sacrificing reconstruction accuracy. Extensive experimental results on large publicly available datasets indicate superiority compared to the most state-of-the-art.
Im2Haircut: Single-view Strand-based Hair Reconstruction for Human Avatars
Vanessa Sklyarova, Egor Zakharov, Malte Prinzler, Giorgio Becherini, Michael J. Black, Justus Thies
1Max Planck Institute for Intelligent Systems
2ETH Zürich
3Technical University of Darmstadt
🚧 Project: https://im2haircut.is.tue.mpg.de/
📄 Paper: https://arxiv.org/pdf/2509.01469
💻 Code: https://github.com/Vanessik/Im2Haircut
❌ ArXiv: https://arxiv.org/abs/2509.01469

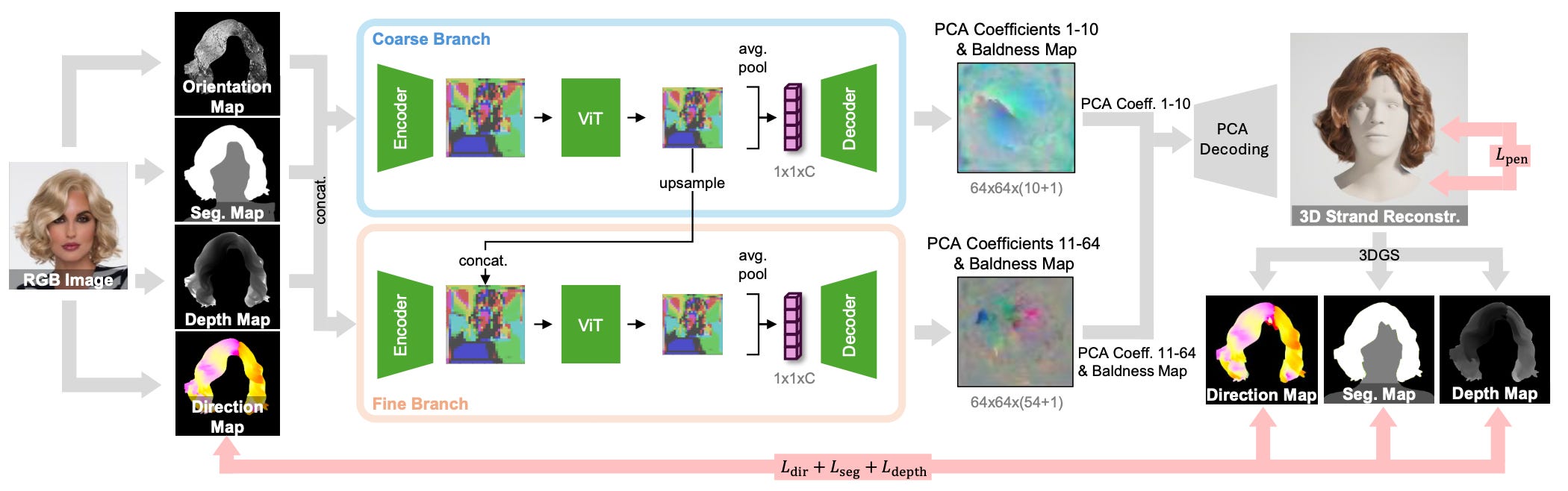
We present a novel approach for 3D hair reconstruction from single photographs based on a global hair prior combined with local optimization. Capturing strand-based hair geometry from single photographs is challenging due to the variety and geometric complexity of hairstyles and the lack of ground truth training data. Classical reconstruction methods like multi-view stereo only reconstruct the visible hair strands, missing the inner structure of hairstyles and hampering realistic hair simulation. To address this, existing methods leverage hairstyle priors trained on synthetic data. Such data, however, is limited in both quantity and quality since it requires manual work from skilled artists to model the 3D hairstyles and create near-photorealistic renderings. To address this, we propose a novel approach that uses both, real and synthetic data to learn an effective hairstyle prior. Specifically, we train a transformer-based prior model on synthetic data to obtain knowledge of the internal hairstyle geometry and introduce real data in the learning process to model the outer structure. This training scheme is able to model the visible hair strands depicted in an input image, while preserving the general 3D structure of hairstyles. We exploit this prior to create a Gaussian-splatting-based reconstruction method that creates hairstyles from one or more images. Qualitative and quantitative comparisons with existing reconstruction pipelines demonstrate the effectiveness and superior performance of our method for capturing detailed hair orientation, overall silhouette, and backside consistency.
MoGA: 3D Generative Avatar Prior for Monocular Gaussian Avatar Reconstruction
Zijian Dong, Longteng Duan, Jie Song, Michael J. Black, Andreas Geiger
🚧 Project: https://zj-dong.github.io/MoGA/
📄 Paper: https://arxiv.org/pdf/2507.23597
❌ ArXiv: https://arxiv.org/abs/2507.23597
💻 Code: https://github.com/zj-dong/MoGA

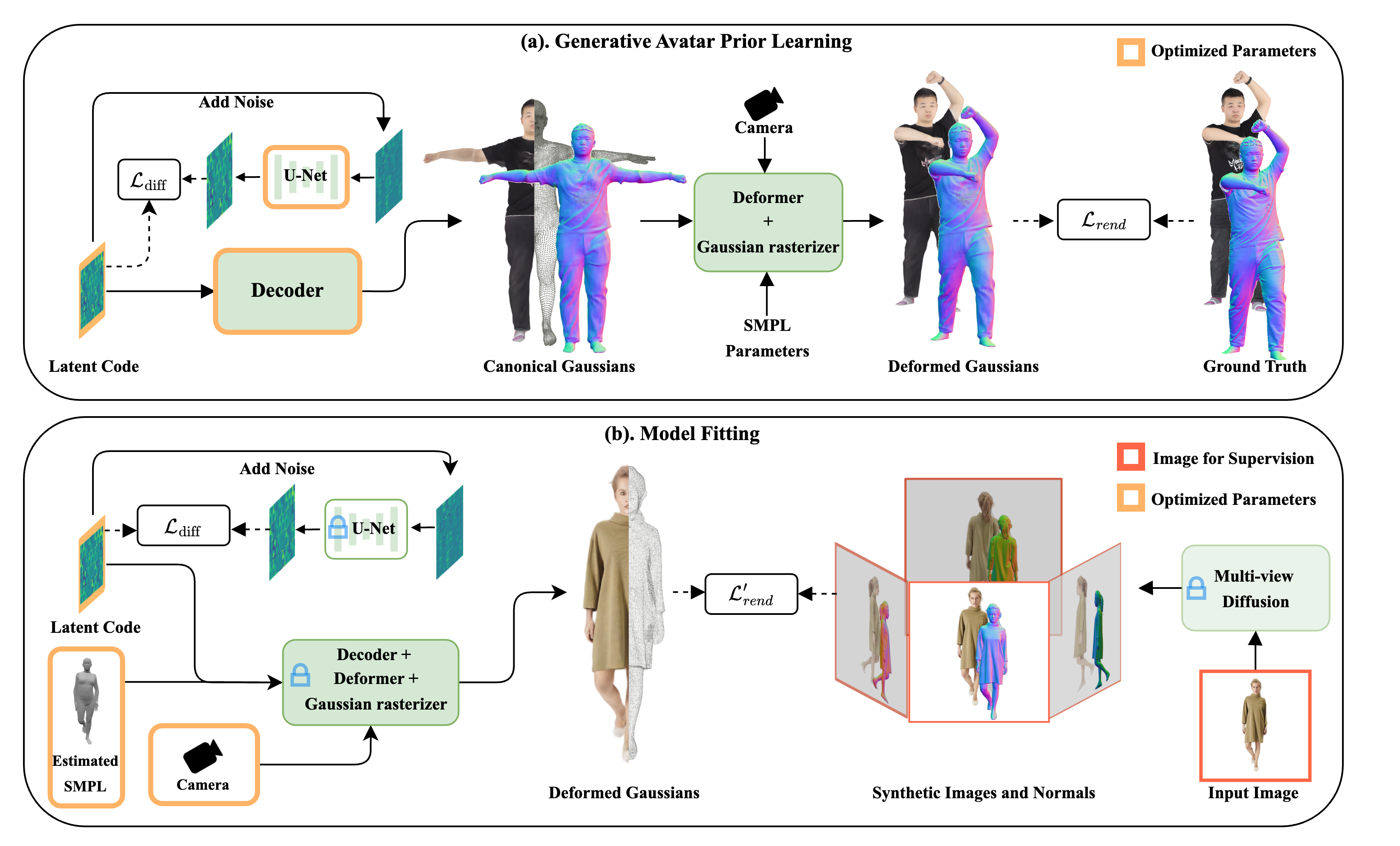
We present MoGA, a novel method to reconstruct high-fidelity 3D Gaussian avatars from a single-view image. The main challenge lies in inferring unseen appearance and geometric details while ensuring 3D consistency and realism. Most previous methods rely on 2D diffusion models to synthesize unseen views; however, these generated views are sparse and inconsistent, resulting in unrealistic 3D artifacts and blurred appearance. To address these limitations, we leverage a generative avatar model, that can generate diverse 3D avatars by sampling deformed Gaussians from a learned prior distribution. Due to limited 3D training data, such a 3D model alone cannot capture all image details of unseen identities. Consequently, we integrate it as a prior, ensuring 3D consistency by projecting input images into its latent space and enforcing additional 3D appearance and geometric constraints. Our novel approach formulates Gaussian avatar creation as model inversion by fitting the generative avatar to synthetic views from 2D diffusion models. The generative avatar provides an initialization for model fitting, enforces 3D regularization, and helps in refining pose. Experiments show that our method surpasses state-of-the-art techniques and generalizes well to real-world scenarios. Our Gaussian avatars are also inherently animatable.