
Today in Character Technology - 10/21/25
Compression for Streamable 3D Avatars, Head and Hand contacts, A new Large-scale dataset from Meta, Semantically meaningful Co-Speech Gestures, and more...

Couple highlights from today’s drop that may not be obvious if you’re just glancing through.
Meta’s Codec Avatar Lab has released a large new human motion/behavior dataset composed of 500 hours of motion data from 439 individuals. A valuable new dataset for anyone doing research in this area.
ImaGGen does something I haven’t seen before with Co-Speech Gestures (Co-speech gestures, being a large area of research focusing on generative gesture animation that accompanies human speaking). Most co-speech gesture research focuses on, what the authors here describe as “simple, repetitive beat gestures that accompany the rhythm of speaking but do not contribute to communicating semantic meaning.” But this work focuses on semantically meaningful gestures, such as the use of hands to visually describe the shape of a book case or water fountain.
While their work is still somewhat crude, it represents an important vector in co-speech gesture generation. Some examples on their project page.
Cheers!
HGC-Avatar: Hierarchical Gaussian Compression for Streamable Dynamic 3D Avatars
Haocheng Tang, Ruoke Yan, Xinhui Yin, Qi Zhang, Xinfeng Zhang, Siwei Ma, Wen Gao, Chuanmin Jia
State Key Laboratory of Multimedia Information Processing, School of Computer Science, Peking University.BeijingChina
🚧 Project: N/A
📄 Paper: https://arxiv.org/pdf/2510.16463
❌ ArXiv: https://arxiv.org/abs/2510.16463
💻 Code: N/A
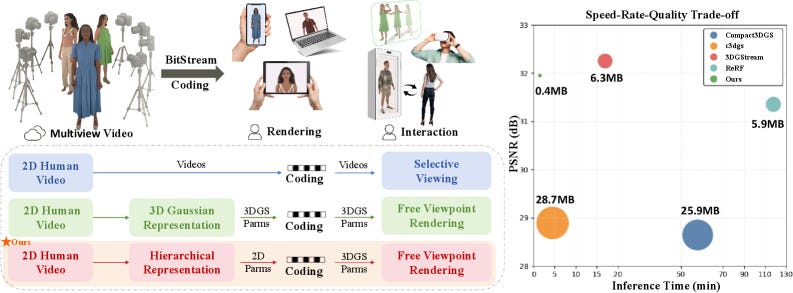
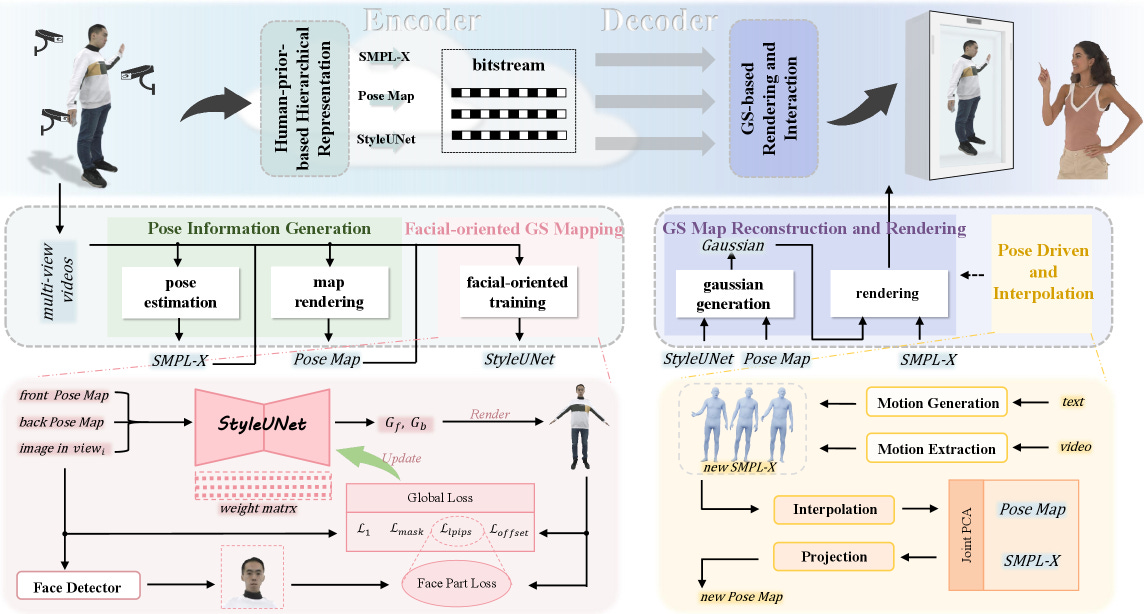
Recent advances in 3D Gaussian Splatting (3DGS) have enabled fast, photorealistic rendering of dynamic 3D scenes, showing strong potential in immersive communication. However, in digital human encoding and transmission, the compression methods based on general 3DGS representations are limited by the lack of human priors, resulting in suboptimal bitrate efficiency and reconstruction quality at the decoder side, which hinders their application in streamable 3D avatar systems. We propose HGC-Avatar, a novel Hierarchical Gaussian Compression framework designed for efficient transmission and high-quality rendering of dynamic avatars. Our method disentangles the Gaussian representation into a structural layer, which maps poses to Gaussians via a StyleUNet-based generator, and a motion layer, which leverages the SMPL-X model to represent temporal pose variations compactly and semantically. This hierarchical design supports layer-wise compression, progressive decoding, and controllable rendering from diverse pose inputs such as video sequences or text. Since people are most concerned with facial realism, we incorporate a facial attention mechanism during StyleUNet training to preserve identity and expression details under low-bitrate constraints. Experimental results demonstrate that HGC-Avatar provides a streamable solution for rapid 3D avatar rendering, while significantly outperforming prior methods in both visual quality and compression efficiency.
Capturing Head Avatar with Hand Contacts from a Monocular Video
Haonan He, Yufeng Zheng, Jie Song
1The Hong Kong University of Science and Technology (Guangzhou)
2The Hong Kong University of Science and Technology
3ETH Zürich, Switzerland
4Max Planck Institute for Intelligent Systems, Tübingen, Germany
🚧 Project: N/A
📄 Paper: https://arxiv.org/pdf/2510.17181
❌ ArXiv: https://arxiv.org/abs/2510.17181
💻 Code: N/A
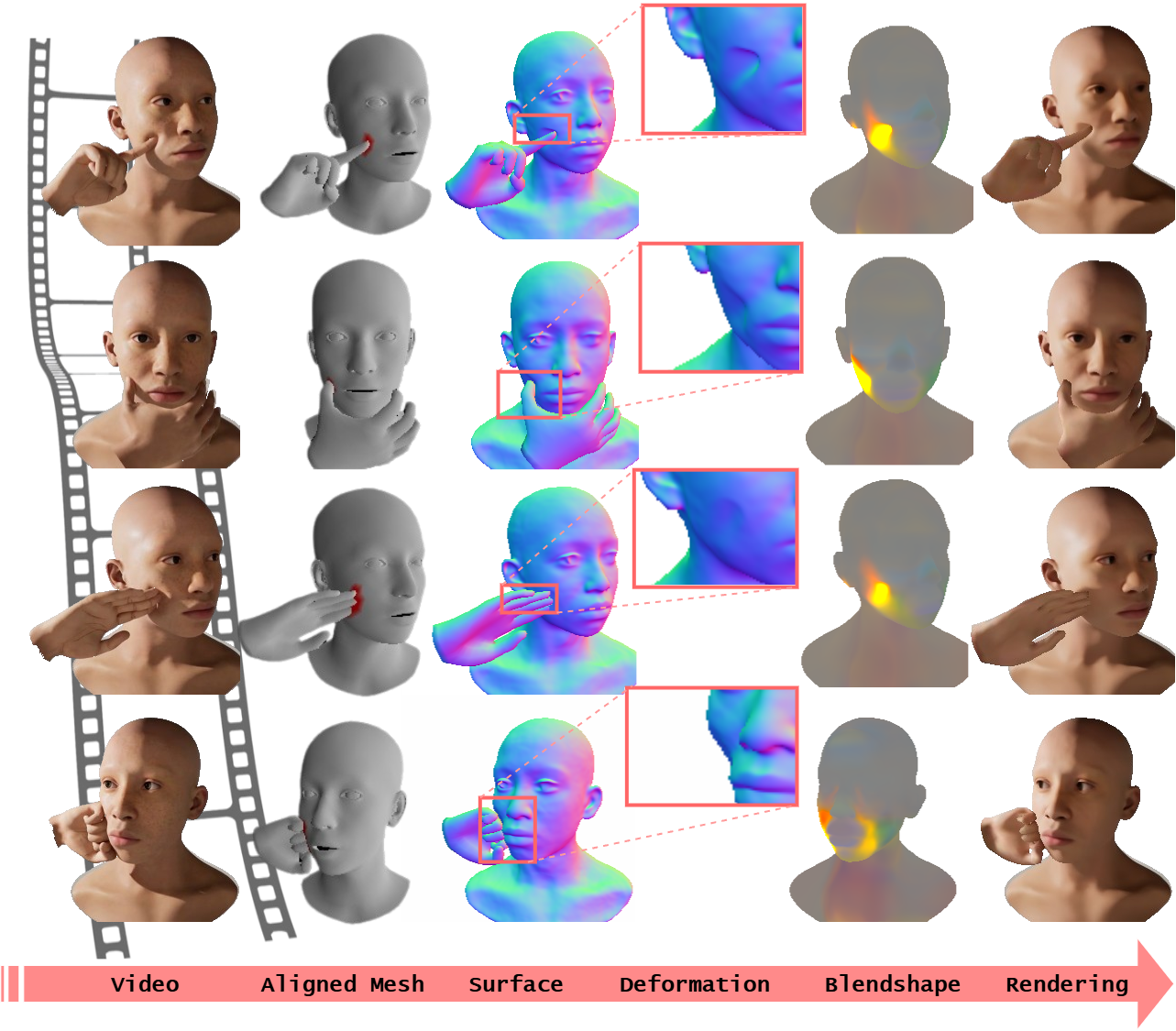
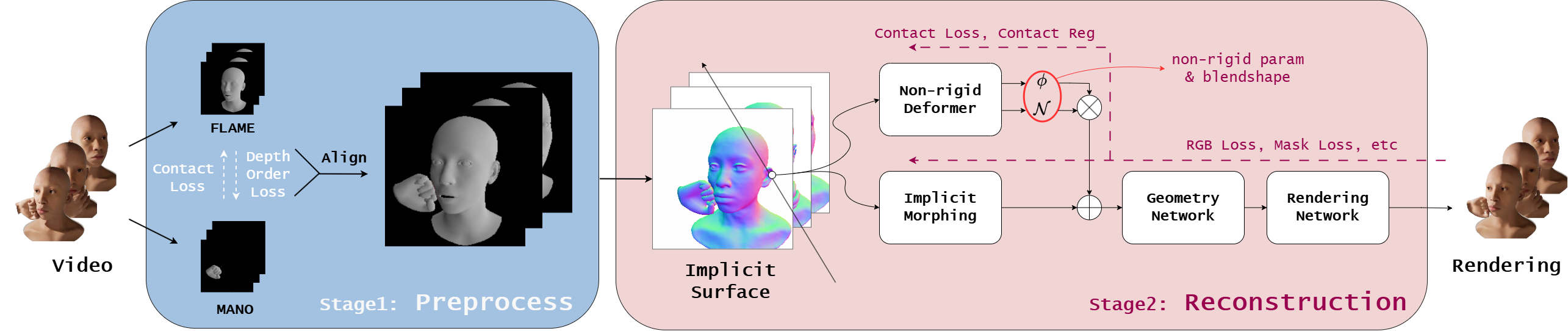
Photorealistic 3D head avatars are vital for telepresence, gaming, and VR. However, most methods focus solely on facial regions, ignoring natural hand-face interactions, such as a hand resting on the chin or fingers gently touching the cheek, which convey cognitive states like pondering. In this work, we present a novel framework that jointly learns detailed head avatars and the non-rigid deformations induced by hand-face interactions.
There are two principal challenges in this task. First, naively tracking hand and face separately fails to capture their relative poses. To overcome this, we propose to combine depth order loss with contact regularization during pose tracking, ensuring correct spatial relationships between the face and hand. Second, no publicly available priors exist for hand-induced deformations, making them non-trivial to learn from monocular videos. To address this, we learn a PCA basis specific to hand-induced facial deformations from a face-hand interaction dataset. This reduces the problem to estimating a compact set of PCA parameters rather than a full spatial deformation field. Furthermore, inspired by physics-based simulation, we incorporate a contact loss that provides additional supervision, significantly reducing interpenetration artifacts and enhancing the physical plausibility of the results.
We evaluate our approach on RGB(D) videos captured by an iPhone. Additionally, to better evaluate the reconstructed geometry, we construct a synthetic dataset of avatars with various types of hand interactions. We show that our method can capture better appearance and more accurate deforming geometry of the face than SOTA surface reconstruction methods.
Embody 3D: A Large-scale Multimodal Motion and Behavior Dataset
Claire McLean, Makenzie Meendering, Tristan Swartz, Orri Gabbay, Alexandra Olsen, Rachel Jacobs, Nicholas Rosen, Philippe de Bree, Tony Garcia, Gadsden Merrill, Jake Sandakly, Julia Buffalini, Neham Jain, Steven Krenn, Moneish Kumar, Dejan Markovic, Evonne Ng, Fabian Prada, Andrew Saba, Siwei Zhang, Vasu Agrawal, Tim Godisart, Alexander Richard, Michael Zollhoefer
Codec Avatars Lab, Meta
🚧 Project: https://www.meta.com/emerging-tech/codec-avatars/embody-3d/
📄 Paper: https://arxiv.org/pdf/2510.16258
❌ ArXiv: https://arxiv.org/abs/2510.16258
🗃️Dataset: https://www.meta.com/emerging-tech/codec-avatars/embody-3d

The Codec Avatars Lab at Meta introduces Embody 3D, a multimodal dataset of 500 individual hours of 3D motion data from 439 participants collected in a multi-camera collection stage, amounting to over 54 million frames of tracked 3D motion. The dataset features a wide range of single-person motion data, including prompted motions, hand gestures, and locomotion; as well as multi-person behavioral and conversational data like discussions, conversations in different emotional states, collaborative activities, and co-living scenarios in an apartment-like space. We provide tracked human motion including hand tracking and body shape, text annotations, and a separate audio track for each participant.
ImaGGen: Zero-Shot Generation of Co-Speech Semantic Gestures Grounded in Language and Image Input
Social Cognitive Systems Group, Bielefeld UniversityUniversitätsstraße 25Germany
🚧 Project: https://review-anon-io.github.io/ImaGGen.github.io/
📄 Paper: https://arxiv.org/pdf/2510.17617
❌ ArXiv: https://arxiv.org/abs/2510.17617
💻 Code: (coming…)
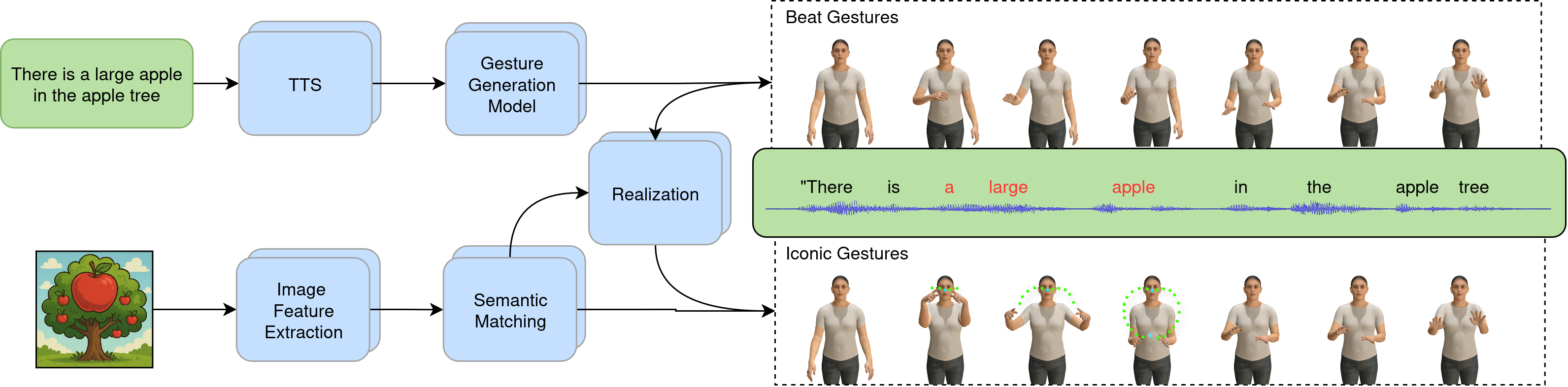
Human communication combines speech with expressive nonverbal cues such as hand gestures that serve manifold communicative functions. Yet, current generative gesture generation approaches are restricted to simple, repetitive beat gestures that accompany the rhythm of speaking but do not contribute to communicating semantic meaning. This paper tackles a core challenge in co-speech gesture synthesis: generating iconic or deictic gestures that are semantically coherent with a verbal utterance. Such gestures cannot be derived from language input alone, which inherently lacks the visual meaning that is often carried autonomously by gestures. We therefore introduce a zero-shot system that generates gestures from a given language input and additionally is informed by imagistic input, without manual annotation or human intervention. Our method integrates an image analysis pipeline that extracts key object properties such as shape, symmetry, and alignment, together with a semantic matching module that links these visual details to spoken text. An inverse kinematics engine then synthesizes iconic and deictic gestures and combines them with co-generated natural beat gestures for coherent multimodal communication. A comprehensive user study demonstrates the effectiveness of our approach. In scenarios where speech alone was ambiguous, gestures generated by our system significantly improved participants’ ability to identify object properties, confirming their interpretability and communicative value. While challenges remain in representing complex shapes, our results highlight the importance of context-aware semantic gestures for creating expressive and collaborative virtual agents or avatars, marking a substantial step forward towards efficient and robust, embodied human-agent interaction
SPLite Hand: Sparsity-Aware Lightweight 3D Hand Pose Estimation
Yeh Keng Hao, Hsu Tzu Wei, Sun Min
National Tsing Hua University Taiwan
🚧 Project: N/A
📄 Paper: https://arxiv.org/pdf/2510.16396
❌ ArXiv: https://arxiv.org/abs/2510.16396
💻 Code: N/A

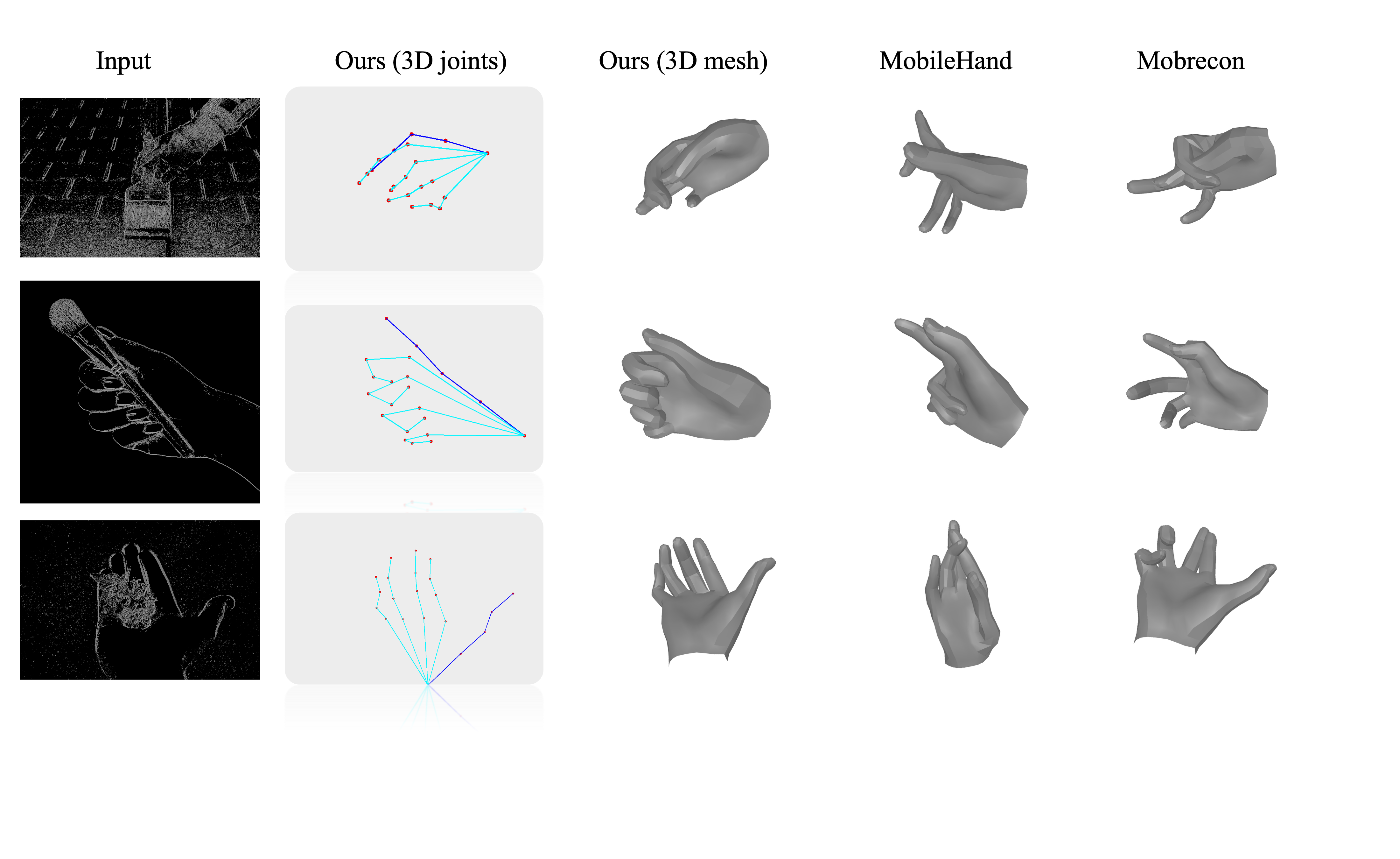
With the increasing ubiquity of AR/VR devices, the deployment of deep learning models on edge devices has become a critical challenge. These devices require real-time inference, low power consumption, and minimal latency. Many framework designers face the conundrum of balancing efficiency and performance. We design a light framework that adopts an encoder-decoder architecture and introduces several key contributions aimed at improving both efficiency and accuracy. We apply sparse convolution on a ResNet-18 backbone to exploit the inherent sparsity in hand pose images, achieving a 42% end-to-end efficiency improvement. Moreover, we propose our SPLite decoder. This new architecture significantly boosts the decoding process’s frame rate by 3.1x on the Raspberry Pi 5, while maintaining accuracy on par. To further optimize performance, we apply quantization-aware training, reducing memory usage while preserving accuracy (PA-MPJPE increases only marginally from 9.0 mm to 9.1 mm on FreiHAND). Overall, our system achieves a 2.98x speed-up on a Raspberry Pi 5 CPU (BCM2712 quad-core Arm A76 processor). Our method is also evaluated on compound benchmark datasets, demonstrating comparable accuracy to state-of-the-art approaches while significantly enhancing computational efficiency.
Conveying Meaning through Gestures: An Investigation into Semantic Co-Speech Gesture Generation
Hendric Voss, Lisa Michelle Bohnenkamp, Stefan Kopp
📄 Paper: https://arxiv.org/abs/2510.17599
This study explores two frameworks for co-speech gesture generation, AQ-GT and its semantically-augmented variant AQ-GT-a, to evaluate their ability to convey meaning through gestures and how humans perceive the resulting movements. Using sentences from the SAGA spatial communication corpus, contextually similar sentences, and novel movement-focused sentences, we conducted a user-centered evaluation of concept recognition and human-likeness. Results revealed a nuanced relationship between semantic annotations and performance. The original AQ-GT framework, lacking explicit semantic input, was surprisingly more effective at conveying concepts within its training domain. Conversely, the AQ-GT-a framework demonstrated better generalization, particularly for representing shape and size in novel contexts. While participants rated gestures from AQ-GT-a as more expressive and helpful, they did not perceive them as more human-like. These findings suggest that explicit semantic enrichment does not guarantee improved gesture generation and that its effectiveness is highly dependent on the context, indicating a potential trade-off between specialization and generalization.’
Thanks for writing this, it clarifies a lot. The ImaGGen work on semantically meaningful gestures is really fascinating and something I hadn't considered as a separate research path beyond just beat gestures. I wonder though how well these generative models can truly capture the subtle, often unconscious variations that make human communication so rich, especialy outside of predefined actions.