
Today in Character Technology - 10/20/25
Mobile Gaussian Avatars

Instant Skinned Gaussian Avatars for Web, Mobile and VR Applications
Naruya Kondo, Yuto Asano, Yoichi Ochiai
University of Tsukuba, Japan
🚧 Project: https://sites.google.com/view/gaussian-vrm
📄 Paper: https://arxiv.org/pdf/2510.13978
❌ ArXiv: https://arxiv.org/abs/2510.13978
💻 Code: (coming soon)

We present Instant Skinned Gaussian Avatars, a real-time and cross-platform 3D avatar system. Many approaches have been proposed to animate Gaussian Splatting, but they often require camera arrays, long preprocessing times, or high-end GPUs. Some methods attempt to convert Gaussian Splatting into mesh-based representations, achieving lightweight performance but sacrificing visual fidelity. In contrast, our system efficiently animates Gaussian Splatting by leveraging parallel splat-wise processing to dynamically follow the underlying skinned mesh in real time while preserving high visual fidelity. From smartphone-based 3D scanning to on-device preprocessing, the entire process takes just around five minutes, with the avatar generation step itself completed in only about 30 seconds. Our system enables users to instantly transform their real-world appearance into a 3D avatar, making it ideal for seamless integration with social media and metaverse applications.
HRM^2Avatar: High-Fidelity Real-Time Mobile Avatars from Monocular Phone Scans
Chao Shi, Shenghao Jia, Jinhui Liu, Yong Zhang, Liangchao Zhu, Zhonglei Yang, Jinze Ma, Chaoyue Niu, Chengfei Lv
Shanghai Jiao Tong University, China
Alibaba Group, China
🚧 Project: https://acennr-engine.github.io/HRM2Avatar/
📄 Paper: https://arxiv.org/pdf/2510.13587.pdf
❌ ArXiv: https://arxiv.org/abs/2510.13587.pdf
💻 Code: (coming soon)
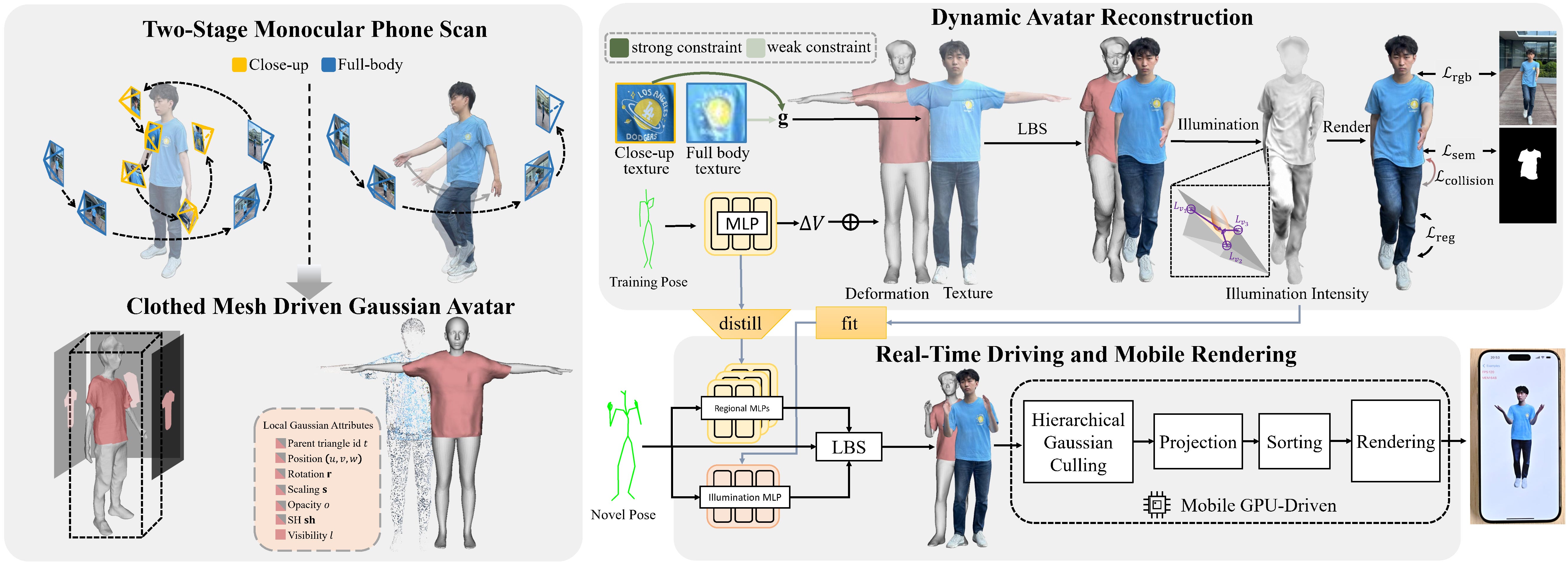
We present HRM Avatar, a framework for creating high-fidelity avatars from monocular phone scans, which can be rendered and animated in real time on mobile devices. Monocular capture with smartphones provides a low-cost alternative to studio-grade multi-camera rigs, making avatar digitization accessible to non-expert users. Reconstructing high-fidelity avatars from single-view video sequences poses challenges due to limited visual and geometric data. To address these limitations, at the data level, our method leverages two types of data captured with smartphones: static pose sequences for texture reconstruction and dynamic motion sequences for learning pose-dependent deformations and lighting changes. At the representation level, we employ a lightweight yet expressive representation to reconstruct high-fidelity digital humans from sparse monocular data. We extract garment meshes from monocular data to model clothing deformations effectively, and attach illumination-aware Gaussians to the mesh surface, enabling high-fidelity rendering and capturing pose-dependent lighting. This representation efficiently learns high-resolution and dynamic information from monocular data, enabling the creation of detailed avatars. At the rendering level, real-time performance is critical for animating high-fidelity avatars in AR/VR, social gaming, and on-device creation. Our GPU-driven rendering pipeline delivers 120 FPS on mobile devices and 90 FPS on standalone VR devices at 2K resolution, over faster than representative mobile-engine baselines. Experiments show that HRMAvatar delivers superior visual realism and real-time interactivity, outperforming state-of-the-art monocular methods.