
Today in Character Technology - 10/14/25
Implicit 3DMM for Localized Head Modeling, Infinite 3D Human Creation, Synchronous 2D & 3D Generative Models for Single View Human Construction, Audio/Pose Driven Half-Body Animation

ImHead: A Large-scale Implicit Morphable Model for Localized Head Modeling
Rolandos Alexandros Potamias, Stathis Galanakis, Jiankang Deng, Athanasios Papaioannou, Stefanos Zafeiriou
Imperial College London
🚧 Project: https://rolpotamias.github.io/imHead/
📄 Paper: https://arxiv.org/pdf/2510.10793
💻 Code: https://rolpotamias.github.io/imHead/
❌ ArXiv: https://arxiv.org/abs/2510.10793

Over the last years, 3D morphable models (3DMMs) have emerged as a state-of-the-art methodology for modeling and generating expressive 3D avatars. However, given their reliance on a strict topology, along with their linear nature, they struggle to represent complex full-head shapes. Following the advent of deep implicit functions, we propose imHead, a novel implicit 3DMM that not only models expressive 3D head avatars but also facilitates localized editing of the facial features. Previous methods directly divided the latent space into local components accompanied by an identity encoding to capture the global shape variations, leading to expensive latent sizes. In contrast, we retain a single compact identity space and introduce an intermediate region-specific latent representation to enable local edits. To train imHead, we curate a large-scale dataset of 4K distinct identities, making a step-towards large scale 3D head modeling. Under a series of experiments we demonstrate the expressive power of the proposed model to represent diverse identities and expressions outperforming previous approaches. Additionally, the proposed approach provides an interpretable solution for 3D face manipulation, allowing the user to make localized edits.
InfiniHuman: Infinite 3D Human Creation with Precise Control
Yuxuan Xue, Xianghui Xie, Margaret Kostyrko, Gerard Pons-Moll
1University of Tübingen,
2Tübingen AI Center,
3Max Planck Institute for Informatics, Saarland Informatics Campus
🚧 Project: https://yuxuan-xue.com/infini-human/
📄 Paper: https://yuxuan-xue.com/infini-human/paper/infinihuman.pdf
💻 Code: https://github.com/YuxuanSnow/InfiniHuman/
❌ ArXiv: https://arxiv.org/abs/2510.11650
Generating realistic and controllable 3D human avatars is a long-standing challenge, particularly when covering broad attribute ranges such as ethnicity, age, clothing styles, and detailed body shapes. Capturing and annotating large-scale human datasets for training generative models is prohibitively expensive and limited in scale and diversity. The central question we address in this paper is: Can existing foundation models be distilled to generate theoretically unbounded, richly annotated 3D human data? We introduce InfiniHuman, a framework that synergistically distills these models to produce richly annotated human data at minimal cost and with theoretically unlimited scalability. We propose InfiniHumanData, a fully automatic pipeline that leverages vision-language and image generation models to create a large-scale multi-modal dataset. User study shows our automatically generated identities are undistinguishable from scan renderings. InfiniHumanData contains 111K identities spanning unprecedented diversity. Each identity is annotated with multi-granularity text descriptions, multi-view RGB images, detailed clothing images, and SMPL body-shape parameters. Building on this dataset, we propose InfiniHumanGen, a diffusion-based generative pipeline conditioned on text, body shape, and clothing assets. InfiniHumanGen enables fast, realistic, and precisely controllable avatar generation. Extensive experiments demonstrate significant improvements over state-of-the-art methods in visual quality, generation speed, and controllability. Our approach enables high-quality avatar generation with fine-grained control at effectively unbounded scale through a practical and affordable solution. We will publicly release the automatic data generation pipeline, the comprehensive InfiniHumanData dataset, and the InfiniHumanGen models at this https URL.
SyncHuman: Synchronizing 2D and 3D Generative Models for Single-view Human Reconstruction
Wenyue Chen, Peng Li, Wangguandong Zheng, Chengfeng Zhao, Mengfei Li, Yaolong Zhu, Zhiyang Dou, Ronggang Wang, Yuan Liu
🚧 Project: https://xishuxishu.github.io/SyncHuman.github.io/
📄 Paper: https://arxiv.org/pdf/2510.07723
💻 Code: https://github.com/IGL-HKUST/SyncHuman
❌ ArXiv: https://arxiv.org/abs/2510.07723

Photorealistic 3D full-body human reconstruction from a single image is a critical yet challenging task for applications in films and video games due to inherent ambiguities and severe self-occlusions. While recent approaches leverage SMPL estimation and SMPL-conditioned image generative models to hallucinate novel views, they suffer from inaccurate 3D priors estimated from SMPL meshes and have difficulty in handling difficult human poses and reconstructing fine details. In this paper, we propose SyncHuman, a novel framework that combines 2D multiview generative model and 3D native generative model for the first time, enabling high-quality clothed human mesh reconstruction from single-view images even under challenging human poses. Multiview generative model excels at capturing fine 2D details but struggles with structural consistency, whereas 3D native generative model generates coarse yet structurally consistent 3D shapes. By integrating the complementary strengths of these two approaches, we develop a more effective generation framework. Specifically, we first jointly fine-tune the multiview generative model and the 3D native generative model with proposed pixel-aligned 2D-3D synchronization attention to produce geometrically aligned 3D shapes and 2D multiview images. To further improve details, we introduce a feature injection mechanism that lifts fine details from 2D multiview images onto the aligned 3D shapes, enabling accurate and high-fidelity reconstruction. Extensive experiments demonstrate that SyncHuman achieves robust and photo-realistic 3D human reconstruction, even for images with challenging poses. Our method outperforms baseline methods in geometric accuracy and visual fidelity, demonstrating a promising direction for future 3D generation models.
VividAnimator: An End-to-End Audio and Pose-driven Half-Body Human Animation Framework
Donglin Huang, Yongyuan Li, Tianhang Liu, Junming Huang, Xiaoda Yang, Chi Wang, Weiwei Xu
1Zhejiang University,
2Image Derivative Inc
🚧 Project: N/A
📄 Paper: https://arxiv.org/pdf/2510.10269
💻 Code: N/A
❌ ArXiv: https://arxiv.org/abs/2510.10269
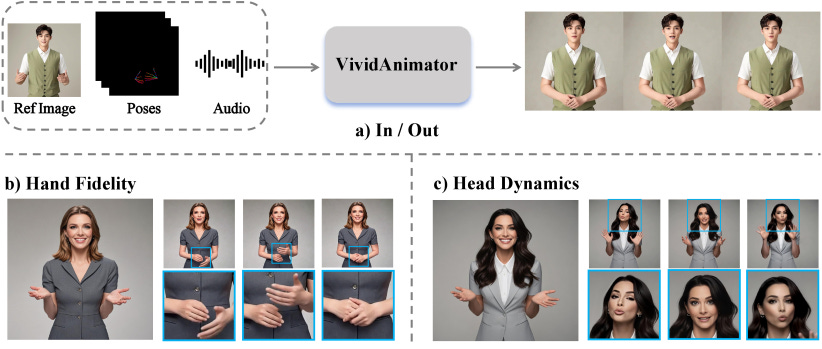
Existing for audio- and pose-driven human animation methods often struggle with stiff head movements and blurry hands, primarily due to the weak correlation between audio and head movements and the structural complexity of hands. To address these issues, we propose VividAnimator, an end-to-end framework for generating high-quality, half-body human animations driven by audio and sparse hand pose conditions. Our framework introduces three key innovations. First, to overcome the instability and high cost of online codebook training, we pre-train a Hand Clarity Codebook (HCC) that encodes rich, high-fidelity hand texture priors, significantly mitigating hand degradation. Second, we design a Dual-Stream Audio-Aware Module (DSAA) to model lip synchronization and natural head pose dynamics separately while enabling interaction. Third, we introduce a Pose Calibration Trick (PCT) that refines and aligns pose conditions by relaxing rigid constraints, ensuring smooth and natural gesture transitions. Extensive experiments demonstrate that Vivid Animator achieves state-of-the-art performance, producing videos with superior hand detail, gesture realism, and identity consistency, validated by both quantitative metrics and qualitative evaluations.
Adjacent Research
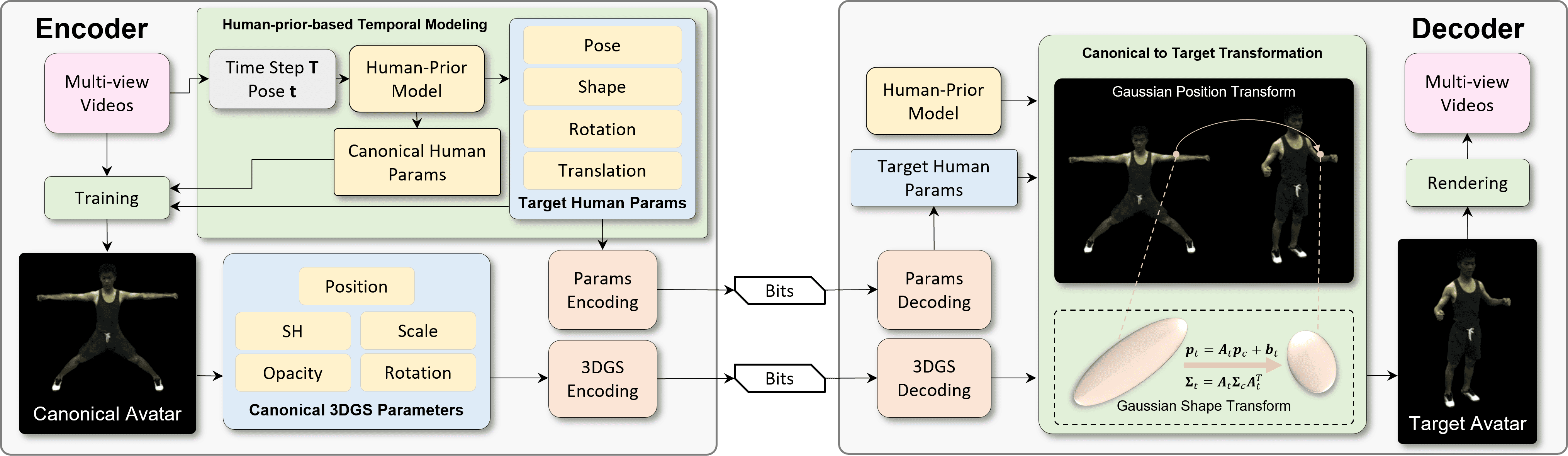
Towards Efficient 3D Gaussian Human Avatar Compression: A Prior-Guided Framework
Shanzhi Yin, Bolin Chen, Xinju Wu, Ru-Ling Liao, Jie Chen, Shiqi Wang, Yan Ye
This paper proposes an efficient 3D avatar coding framework that leverages compact human priors and canonical-to-target transformation to enable high-quality 3D human avatar video compression at ultra-low bit rates.
High-Resolution Spatiotemporal Modeling with Global-Local State Space Models for Video-Based Human Pose Estimation
Runyang Feng, Hyung Jin Chang, Tze Ho Elden Tse, Boeun Kim, Yi Chang, Yixing Gao
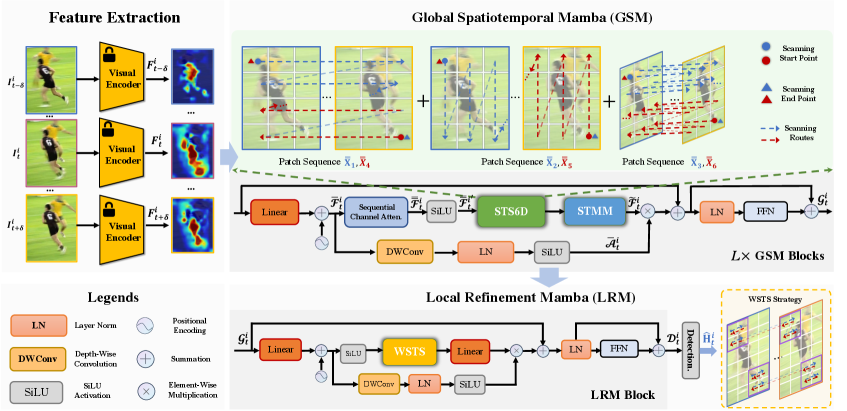
In this paper, we present a novel framework that extends Mamba from two aspects to separately learn global and local high-resolution spatiotemporal representations for VHPE. Specifically, we first propose a Global Spatiotemporal Mamba, which performs 6D selective space-time scan and spatial- and temporal-modulated scan merging to efficiently extract global representations from high-resolution sequences. We further introduce a windowed space-time scan-based Local Refinement Mamba to enhance the high-frequency details of localized keypoint motions.
MonoSE(3)-Diffusion: A Monocular SE(3) Diffusion Framework for Robust Camera-to-Robot Pose Estimation
Kangjian Zhu, Haobo Jiang, Yigong Zhang, Jianjun Qian, Jian Yang, Jin Xie

We propose MonoSE(3)-Diffusion, a monocular SE(3) diffusion framework that formulates markerless, image-based robot pose estimation as a conditional denoising diffusion process.